基于 Go 1.19
在日常的编程实践中,我们常常将 map 作为一种高效的键值存储结构来使用。然而,在 map 的设计背后,隐藏着一系列关于效率、内存使用和并发处理的复杂权衡。这些权衡不仅影响了 map 的性能表现,也决定了它在不同场景下的适用性。本文将深入探讨 gomap 的设计哲学,揭示这些取舍背后的原理,帮助你更全面地理解并优化 map 的使用。
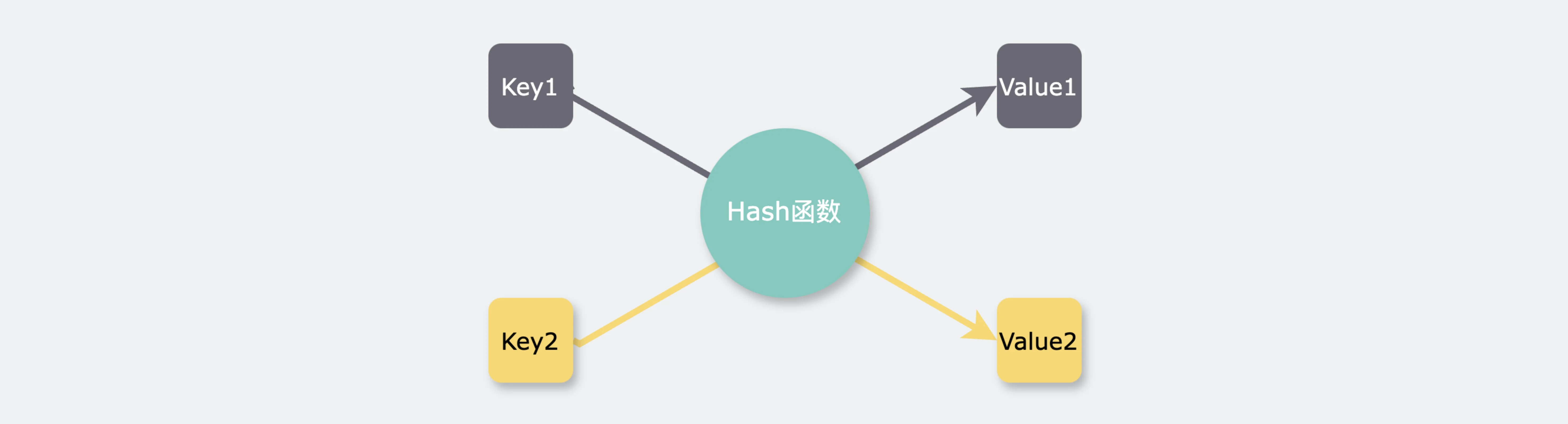
将Map当作KV存储使用
将Map当作KV存储使用
在 map 的设计中,哈希函数(hash function)扮演着至关重要的角色。哈希函数的作用是将任意长度的输入数据(即键)映射到一个固定长度的输出,这个输出通常被称为哈希值(hash value)或摘要(digest)。哈希函数的核心目标是确保不同的键能够均匀地分布在哈希表的各个桶(bucket)中,从而减少冲突,提高查找效率。
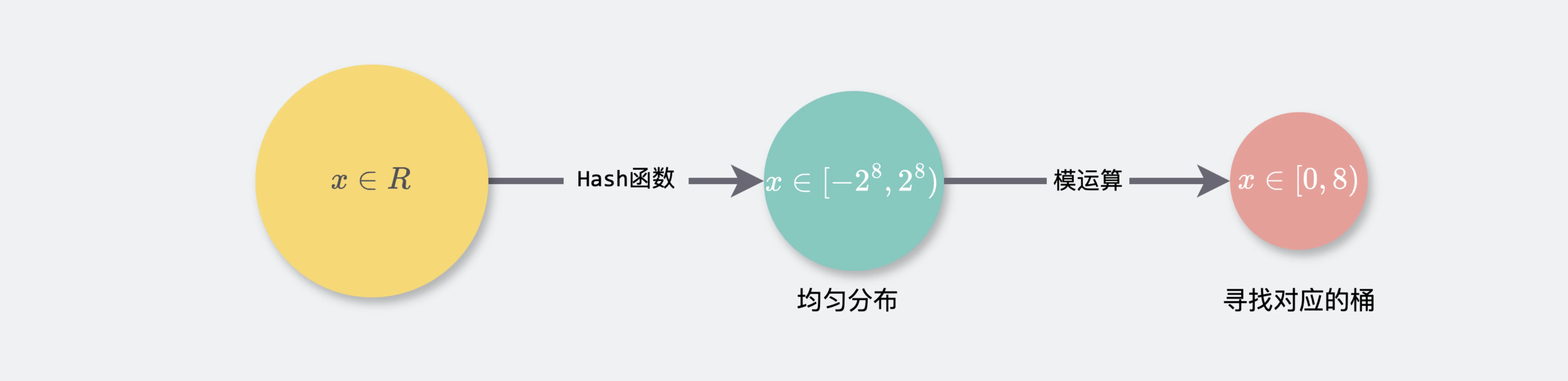
Hash函数将数从实数域随机且均匀地映射到目标域
Hash函数将数从实数域随机且均匀地映射到目标域
Hash 冲突
-
拉链法
拉链法是一种通过在每个散列槽位维护一个链表来处理哈希冲突的散列表方法,它将所有散列到同一位置的元素链接起来,从而允许多个元素共享同一个槽位。拉链法不要求连续的内存空间,但代价是解决冲突时,链表访问效率较低,并且需要额外的空间存储 next 指针
-
开放寻址法
开放寻址法则是将所有元素存储在散列表的连续位置中,当发生冲突时,通过线性探测或其他策略寻找下一个空闲位置,这种方法在空间利用上更为紧凑,但可能需要处理更复杂的冲突解决策略。利用空间局部性原理,在发生冲突时的寻址效率高,但要求连续的空间存储数据。

拉链法与开放寻址法
拉链法与开放寻址法
Go 的 map 实现结合了开放寻址法(open addressing)和拉链法(separate chaining)两种经典的哈希表冲突解决策略,以在不同场景下实现最佳的性能和空间效率。
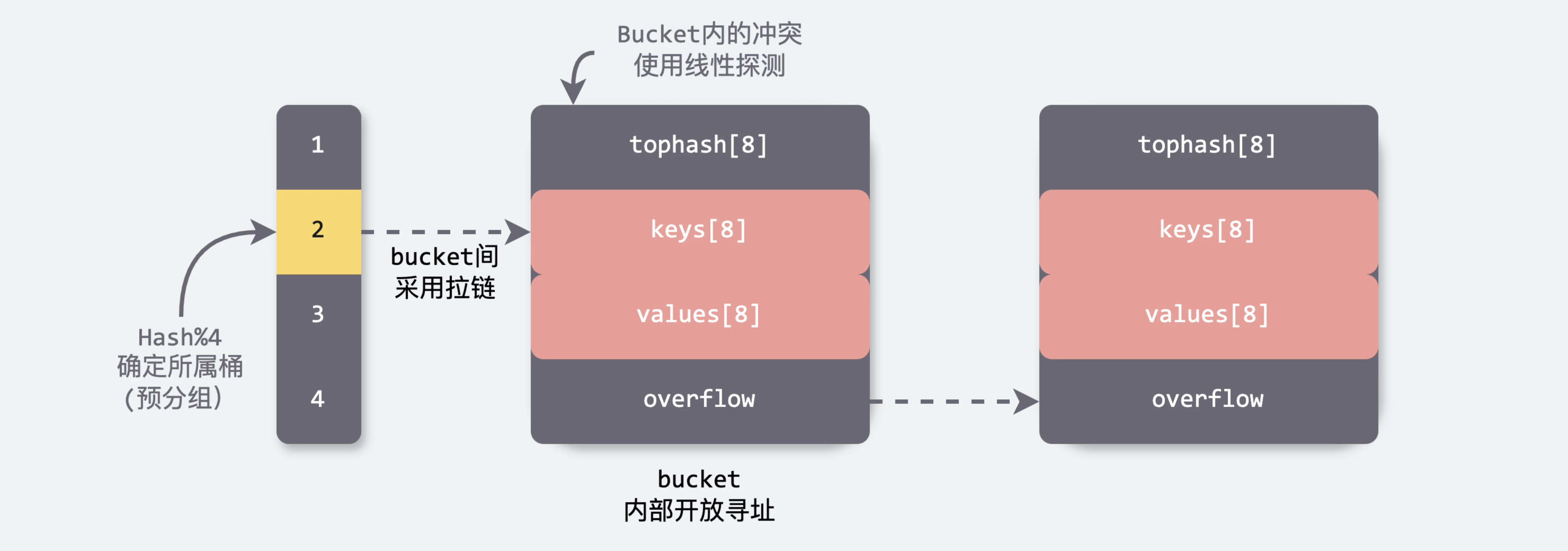
开放寻址法解决hash冲突
开放寻址法解决hash冲突
具体来说,Go 的 map 主要采用了开放寻址法来处理哈希冲突,这种方法通过在哈希表内部(bucket 内部)寻找下一个可用的槽位来存储冲突的键值对,从而避免了额外的内存开销和指针操作。
然而,当哈希表需要扩容时,开放寻址法的效率可能会受到影响,因为扩容过程中需要重新计算所有键的哈希值并重新分配槽位。为了优化这一过程,Go 的 map 实现引入了拉链法作为辅助策略。在扩容时,Go 会将部分冲突的键值对存储在链表中,而不是立即重新分配槽位。这种混合策略不仅减少了扩容时的计算开销,还避免了因频繁扩容而导致的性能波动。
Map 内存模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
type hmap struct {
// 注意:hmap 的格式也编码在 cmd/compile/internal/reflectdata/reflect.go 中。
// 确保它与编译器的定义保持同步。
count int // 活跃单元格的数量等于 map 的大小。必须是第一个(由 len() 内置函数使用)
flags uint8 // 状态标志,表示是否处于写入状态等,用于读写时的冲突
B uint8 // 桶数量的 log_2(最多可以容纳 loadFactor * 2^B 个项目)
noverflow uint16 // 大约的溢出桶数量;有关详细信息,请参阅 incrnoverflow
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 2^B 个桶的数组。如果 count==0,则可能为 nil
oldbuckets unsafe.Pointer // 上一个大小为当前一半的桶数组,仅在增长时非 nil
nevacuate uintptr // 清理进度计数器(小于此值的桶已被清理)
extra *mapextra // 可选字段
}
// Go map 的桶。
type bmap struct {
// tophash 通常包含每个键的哈希值的最高字节。
// 如果 tophash[0] < minTopHash,则 tophash[0] 是一个桶清理状态。
tophash [bucketCnt]uint8
// 然后是 bucketCnt 个键和 bucketCnt 个元素。
// 注意:将所有键一起打包,然后所有元素一起打包使得代码比交替键/元素/键/元素/...更复杂,
// 但它允许我们消除例如 map[int64]int8 所需的填充。
// 然后是一个溢出指针。
}
// mapextra 包含不是所有 map 都有的字段。
type mapextra struct {
// 如果键和元素都不包含指针并且是内联的,那么我们将桶类型标记为不包含指针。
// 这避免了扫描此类映射。
// 然而,bmap.overflow 是一个指针。为了保持溢出桶的活跃状态,
// 我们在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中存储所有溢出桶的指针。
// overflow 和 oldoverflow 仅在键和元素不包含指针时使用。
// overflow 包含 hmap.buckets 的溢出桶。
// oldoverflow 包含 hmap.oldbuckets 的溢出桶。
// 通过间接引用,我们可以在 hiter 中存储对切片的指针。
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow 指向一个空闲的溢出桶。
nextOverflow *bmap
}
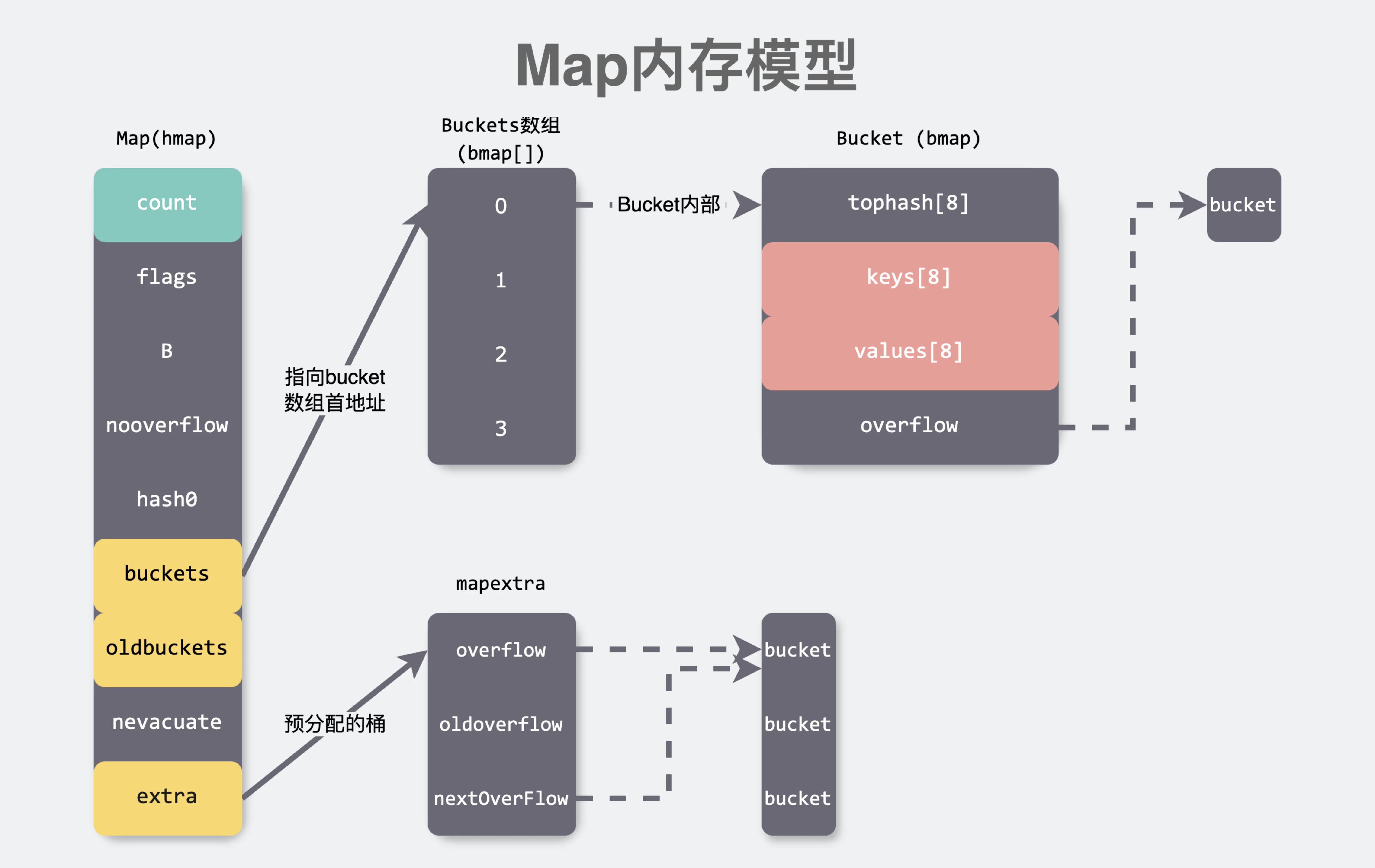
Map内存模型
Map内存模型
map 的实现涉及三种核心结构 hmap、bmap 和 mapextra:
-
hmap(哈希表)是 map 的核心结构,它记录了 map 的整体信息。具体来说,
hmap 包含了以下关键字段:键值对数量:记录当前 map 中存储的键值对总数。
bucket 数组指针:指向存储键值对的桶数组,这是 map 的底层数据结构。
用于拉链法和扩容的额外 bucket:当桶的数量不足以容纳所有键值对时,map 会进行扩容操作,这些额外的 bucket 用于存储新加入的键值对。
其他相关字段:包括用于计算哈希值的种子、当前 map 的状态(如是否正在扩容)等。
-
bmap(桶) 是
hmap 中的一个桶,map 的底层实际上由众多桶组成。每个桶的结构如下:keys 数组:存储桶中所有键的值。
values 数组:存储桶中所有值的值。
overflow 指针:当一个桶存满时,
overflow 指针会指向一个溢出桶,这是拉链法的具体体现。通过这种方式,map 可以在桶满时继续存储新的键值对,而不会立即触发扩容操作。桶结构的许多字段在编译时才会动态生成。这些动态生成的字段本质上是
tophash 的位移偏移值,用于优化内存对齐的开销。将所有 key 集中存放,旨在某些情况下节省内存对齐的开销,从而提高内存使用效率。 -
mapextra(额外信息)存储了一些预先分配的 bucket,以便在需要时快速分配。具体来说,
mapextra 包含以下内容:预分配的 bucket:为了避免频繁的内存分配操作,
mapextra 会预先分配一些 bucket,以便在需要时快速使用。所有溢出桶的引用:
mapextra 还表示所有的溢出桶。之所以需要重新指向这些溢出桶,是为了便于垃圾回收(GC)。通过这种方式,GC 只需扫描所有溢出桶,而不需要扫描整个 map,从而提高了 GC 的效率。
综上所述,hmap、bmap 和 mapextra 这三种结构共同构成了 Go 语言中 map 的内存模型。它们通过高效的内存管理和优化的数据结构,确保了 map 在存储和访问键值对时的高性能表现。
读取流程
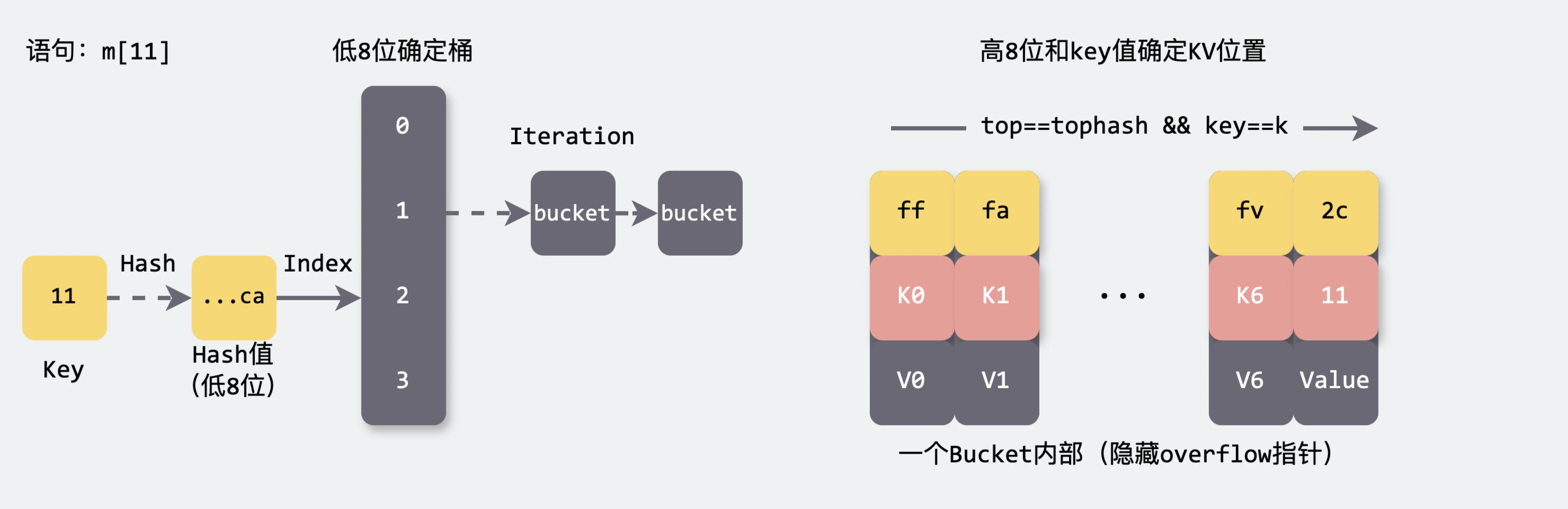
一次读取Key的流程
一次读取Key的流程
-
计算Hash值
首先,使用哈希函数计算(哈希函数由随机种子生成)出Key
11的哈希值2c990b0a82652dca。 -
使用Hash值
2c990b0a82652dca的低八位ca(对应十进制202),来确定键值对所属的桶从数学上讲,获取桶的所属位置是通过模除操作得到的。当前低八位为
ca,对应桶 $202\mod 4=2$。从实现上讲,是通过buckets 的掩码(掩码可由hmap.B 计算得到)与哈希值进行按位与操作& 得到的。 -
确定好所属的桶后,开始遍历所有相连的
bucket。在遍历过程中,会进行以下操作:首先,比较当前槽位的
tophash 值与计算得到的哈希值的高八位部分2c.如果
tophash 不相等,则继续检查tophash 是否为emptyRest,emptyRest表示剩余部分全部为空,此时则可以提前结束遍历。如果
tophash 相等,则进一步比较当前槽位的键与目标键是否相同。如果键相同,则表示找到了目标键值对,返回对应的值。
「源码」
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// mapaccess1 返回对 h[key] 的指针。永远不会返回 nil,而是在键不在映射中时,将返回 elem 类型的零值对象的引用。
// 备注:返回的指针可能保持整个映射的活跃状态,因此不要长时间持有它。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ... 各种安全检查
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
「额外」
➡️ 为什么比较
tophash
tophash 还包含了额外的状态码,例如tophash 为emptyRest 代表后续都是空。这些状态码有助于快速判断槽位的状态,避免不必要的比较操作。
有时候比较键的代价更高,可以先比较
tophash 以稳定查询性能。tophash 的比较操作非常快速,能够显著减少不必要的键比较操作。➡️ 扩容迁移过程中的细微区别
如果当前的桶正在扩容的迁移过程中,比较的流程会有细微的区别。扩容过程中,
map会逐步将旧桶中的数据迁移到新的桶中。在这种情况下,需要首先检查旧的buckets数组中,再检查新的buckets。➡️ 编译器优化部分
Go语言的编译器针对
map的查找操作进行了优化,提供了三个不同的函数:
-
mapaccess1:只返回value的指针,适用于只需要获取value的场景。-
mapaccess2:返回value的指针和一个布尔值,适用于需要判断key是否存在的场景。-
mapaccessK:返回key和value的指针,适用于需要同时获取key和value的场景,如map迭代器。
写入流程(插入或更新)
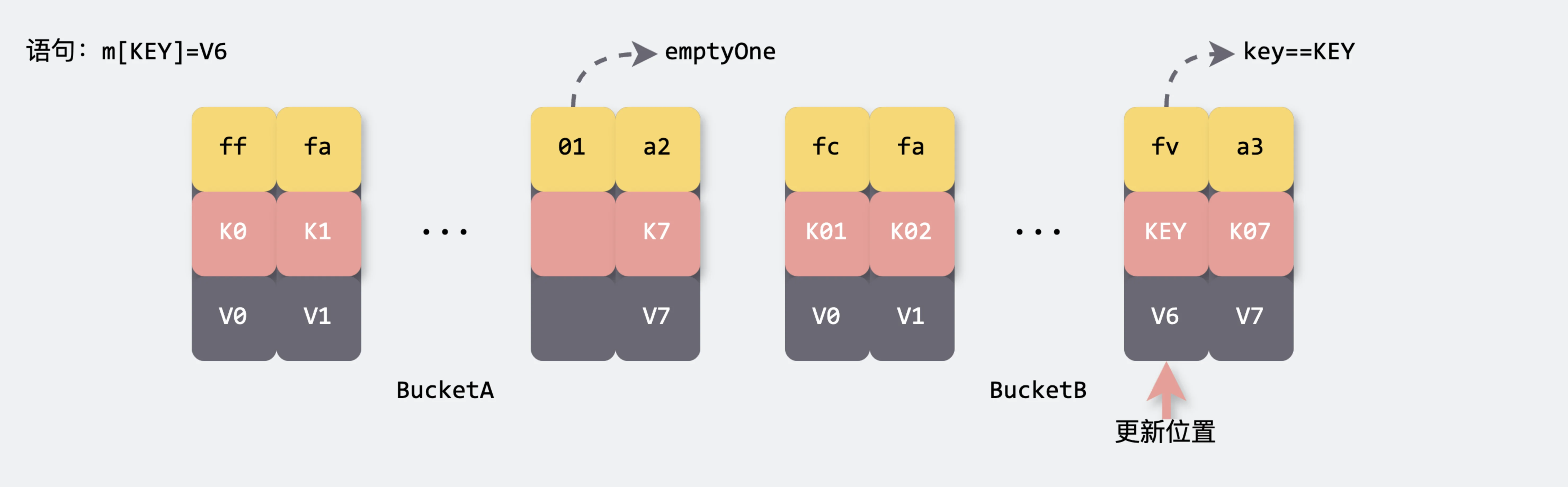
更新流程(bucket内部)
更新流程(bucket内部)
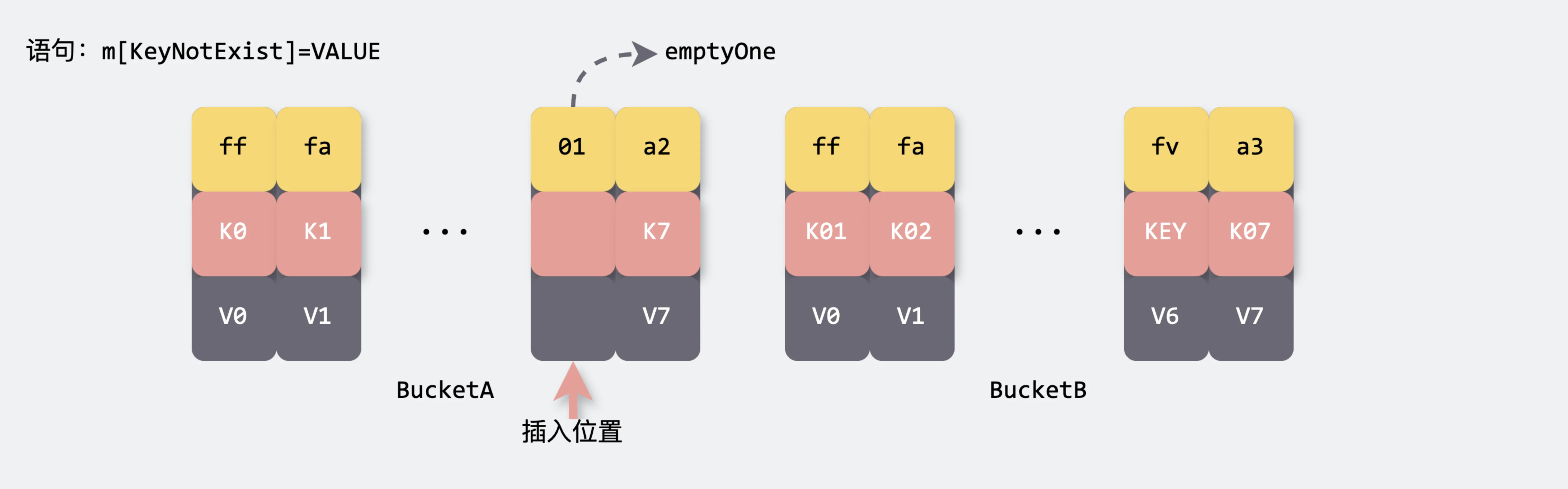
插入流程(bucket内部)
插入流程(bucket内部)
map 写流程主要分为以下几步:
- 计算Hash值
- 确定桶位置
-
处理桶迁移(如果需要)
当Map处于扩容状态时,我们需要对命中的桶进行迁移操作(渐进式扩容)
-
遍历桶链表
在确定所属桶之后,系统会沿着桶链表逐一检查每个桶内的键值对。在此过程中,系统不仅会同时比较 tophash 和 key 值,还会记录下首个空槽的位置,以便于后续插入操作。如果遍历至链表末尾仍未找到匹配项,系统将根据实际情况,考虑创建新的桶。
-
更新或插入键值对
- 更新值:如果找到相同的key,系统将对value进行更新,以反映最新的数据变化。
- 插入键值对:如果key不存在,系统将在当前桶中插入新的key-value对。
-
处理扩容
在写入过程中,如果Map达到扩容条件,系统将开启扩容模式。此时,系统会重新返回到步骤2,对新的桶数组进行操作
「源码」
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ... 各种安全检查
again:
// 找到所属的bucket
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8 // tophash拟插入位置
var insertk unsafe.Pointer // key拟插入位置
var elem unsafe.Pointer // value拟插入位置
bucketloop:
// 遍历bucket和后续溢出桶
for {
for i := uintptr(0); i < bucketCnt; i++ {
// 如果不是
if b.tophash[i] != top {
// 找到第一个为空的位置,便于以后插入
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// 如果找到了key,则更新 | already have a mapping for key. Update it.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
// 寻找下一个溢出桶
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// ... 扩容相关的逻辑
// 找到可插入的地方(当前桶及其所有与之相连的溢出桶都已满),分配一个新的桶。
if inserti == nil {
// The current bucket and all the overflow buckets connected to it are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// ... tophash、KV的插入流程
done:
// ... 末尾的安全检查
return elem
}
删除流程
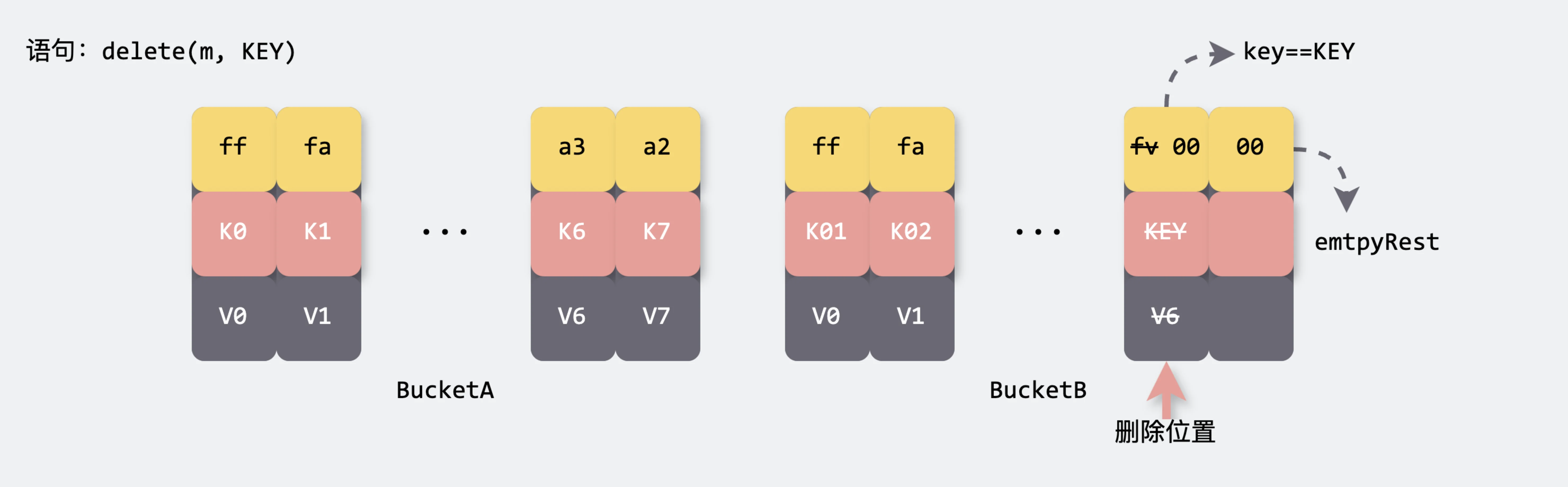
删除流程(bucket内部)
删除流程(bucket内部)
map 删除键值对的流程可以细分为以下几个步骤:
- 计算Hash值
- 确定桶位置
-
处理桶迁移(如果需要)
当Map处于扩容状态时,我们需要对命中的桶进行迁移操作(渐进式扩容)
-
随后,系统会沿着桶链表逐一检查每个桶内的 key-value 对
一旦找到与目标 key 匹配的键值对,系统将删除该对,并将当前位置的 tophash 标记为 emptyOne,以表示该位置已空。
- 最后,如果当前位置是链表的末尾,或者下一个位置的 tophash 为 emptyRest,系统会从当前位置向前遍历,将相邻的 emptyOne 统一更新为 emptyRest,以优化存储结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
// ... 各种安全检查
// 找到所属的bucket
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.key.equal(key, k2) {
continue
}
// 当找到需要删除的节点
// Only clear key if there are pointers in it.
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
//
b.tophash[i] = emptyOne
// If the bucket now ends in a bunch of emptyOne states,
// change those to emptyRest states.
// It would be nice to make this a separate function, but
// for loops are not currently inlineable.
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
h.count--
// Reset the hash seed to make it more difficult for attackers to
// repeatedly trigger hash collisions. See issue 25237.
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}
// ... 结束后的安全检查
}