工具调用与函数调用的函数一致,大模型早期将该行为称为函数调用,后续逐渐更名为工具调用。
工具调用(Tool Calling)是大型语言模型(LLM)应用开发中的关键技术,其本质是让模型具备结构化输出能力。
在大型语言模型(LLM)的应用开发中,一个常见的误区是将工具调用**误认为**是由模型本身直接执行的操作。LLM 本身不直接执行工具调用。模型的核心作用是:
- 理解用户意图
- 判断是否需要调用工具
- 生成结构化调用指令,实际的工具执行由业务系统或外部服务完成。

举个简单的例子:当用户查询「价格在 undefined 元之间的电器」时,模型会分析出用户的需求,并决定调用一个数据库查询工具 database_tool。这一过程要求模型能够精准进行信息抽取,并生成结构化的输出。
了解工具调用机制,需解决的核心问题是理解触发条件的判定逻辑( 换句话说,工具调用的触发机制是怎样的):
- 何时需要触发工具调用?
- 如何选择具体调用的工具?
- 参数提取的准确性如何保证?
本文将从发生工具调用时 LLM 的推理流程入手,从工具调用请求的发送到最终结果的响应,完整解析工具调用的生命周期。
此外,为进一步理解 LLM 为何会响应工具调用请求,本文还给出了 Tool Call 的微调流程。
LLM 的训练流程
这部分介绍了一个大模型从零开始训练都会经历哪几步,给读者一个对大模型的全局了解。
熟悉这部分的读者可以直接跳过。
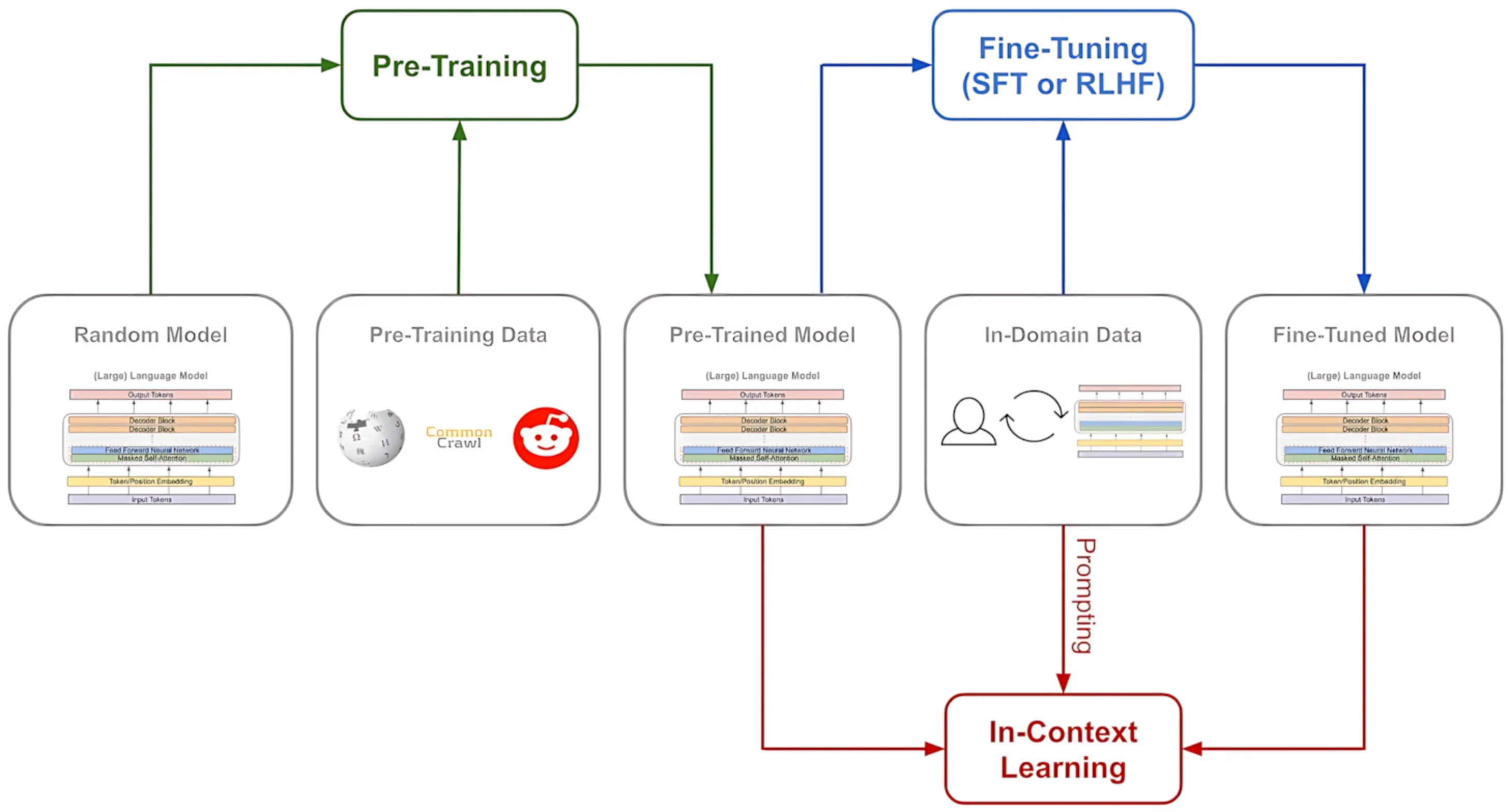
对话大模型的训练数据主要分为通用数据、对话数据和专业数据三大类。其训练流程共分为预训练-微调-对齐(微调和对齐可通常为微调步骤) 三阶段。有时还会额外添加微调流程,例如 DeepSeek 基于 DeepSeekV3 模型和强化学习微调出了 DeepSeekR1 推理模型。
-
预训练阶段(Pretrain) 。预训练阶段通过海量文本学习语言模式,一般是自监督学习范式。在这个过程中,模型学习到了文本的基本范式,具备了生成人类可理解的文字的能力。
- 有监督微调(SFT)。 在预训练基座(Base Model)上注入对话数据(如人工标注的问答对),通过指令微调范式(Instruction Tuning)使模型掌握遵循指令、生成结构化响应的能力。
- 强化学习反馈(RLHF)。 通过人类的偏好、评价或直接指导来优化智能体的行为,使其更符合人类的期望和价值观。通过该阶段,也能优化生成文本的可读性、改变思维方式等。
基本概念
- 「聊天模板」
基于预训练模型构建指令对话模型时,会用到聊天模板来规范每个模型的聊天格式和控制词元。最终让用户的输入以该模板的形式呈现。聊天模板通过 Jinja 模板引擎将对话结构标准化。以 gpt-3.5-turbo 的模板为例:
<|im_start|>system\n你是ChatGPT, 是来帮助人们解决问题的AI模型<|im_end|>
<|im_start|>user\n你好<|im_end|>
<|im_start|>assistant // 给出start标签和角色,期望模型补全对话内容。
其中,特殊控制词元 <|im_start|> 和 <|im_end|> 构成对话边界,system 指令用于定义角色
- 「工具调用能力微调」
工具调用能力的微调可发生在 SFT 或 RLHF 阶段(可统称微调阶段)。
在这过程中,关键是通过标注数据训练模型生成结构化指令。例如,可以将工具描述、参数提取示例作为输入,训练模型生成结构化调用指令。
LLM 的推理流程(工具调用)
接下来,我们将深入探究工具调用时,一轮 LLM 请求的完整生命周期,详细剖析从请求发起直至最终响应的全链路处理流程。在此过程中,我们将以兼容 OpenAI Tool Calling 标准的实现为例展开讲解。
在大型语言模型(LLM)进行工具调用时,整个流程可以分为以下几个关键步骤:
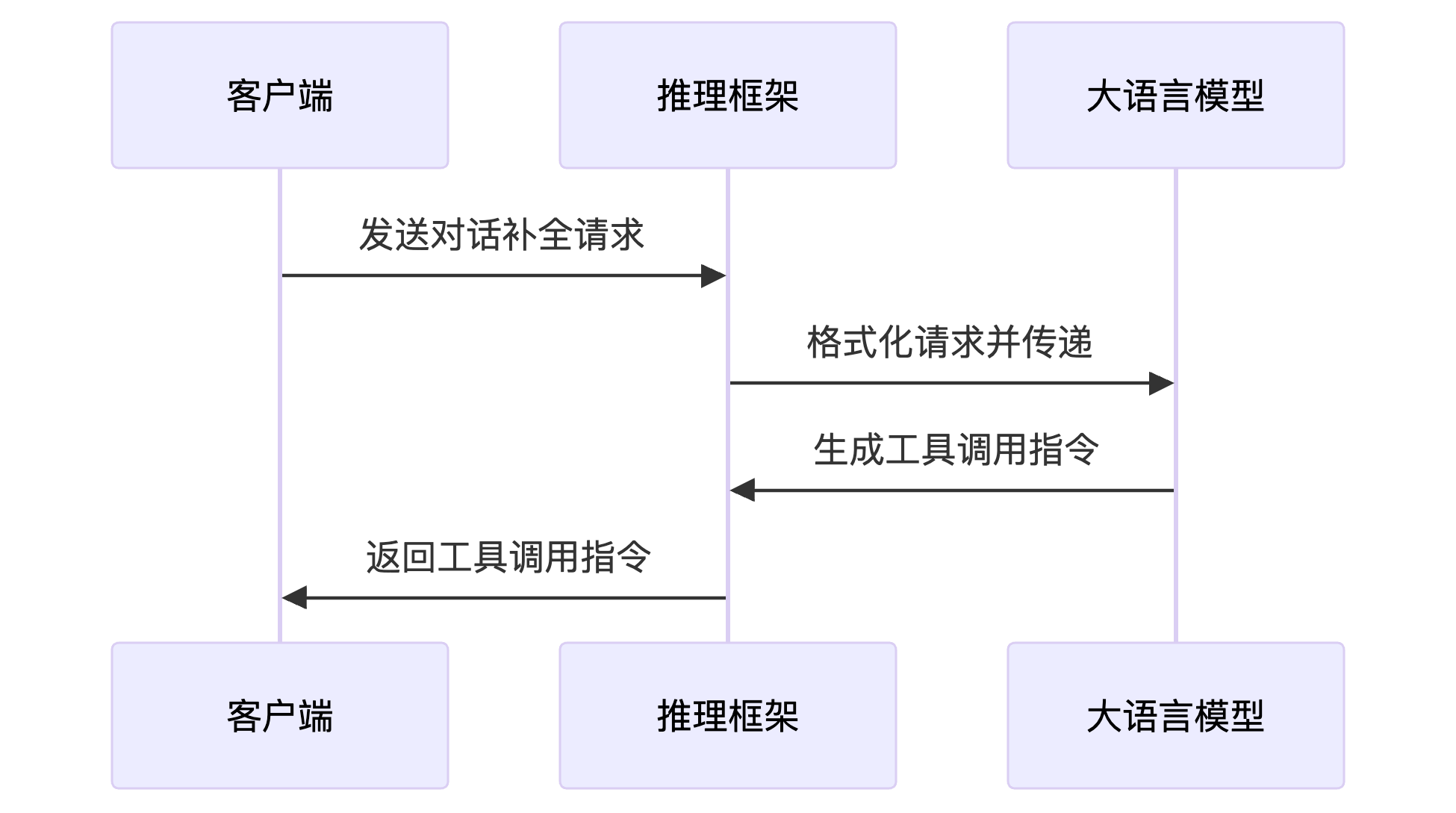
- 对话补全请求发送:包括模型参数、用户消息和工具函数的定义。
- 推理框架处理请求:框架将请求格式化为模型可理解的聊天模板,并传递给模型进行处理。
- 模型响应与工具调用:大模型基于请求内容,生成工具调用指令。
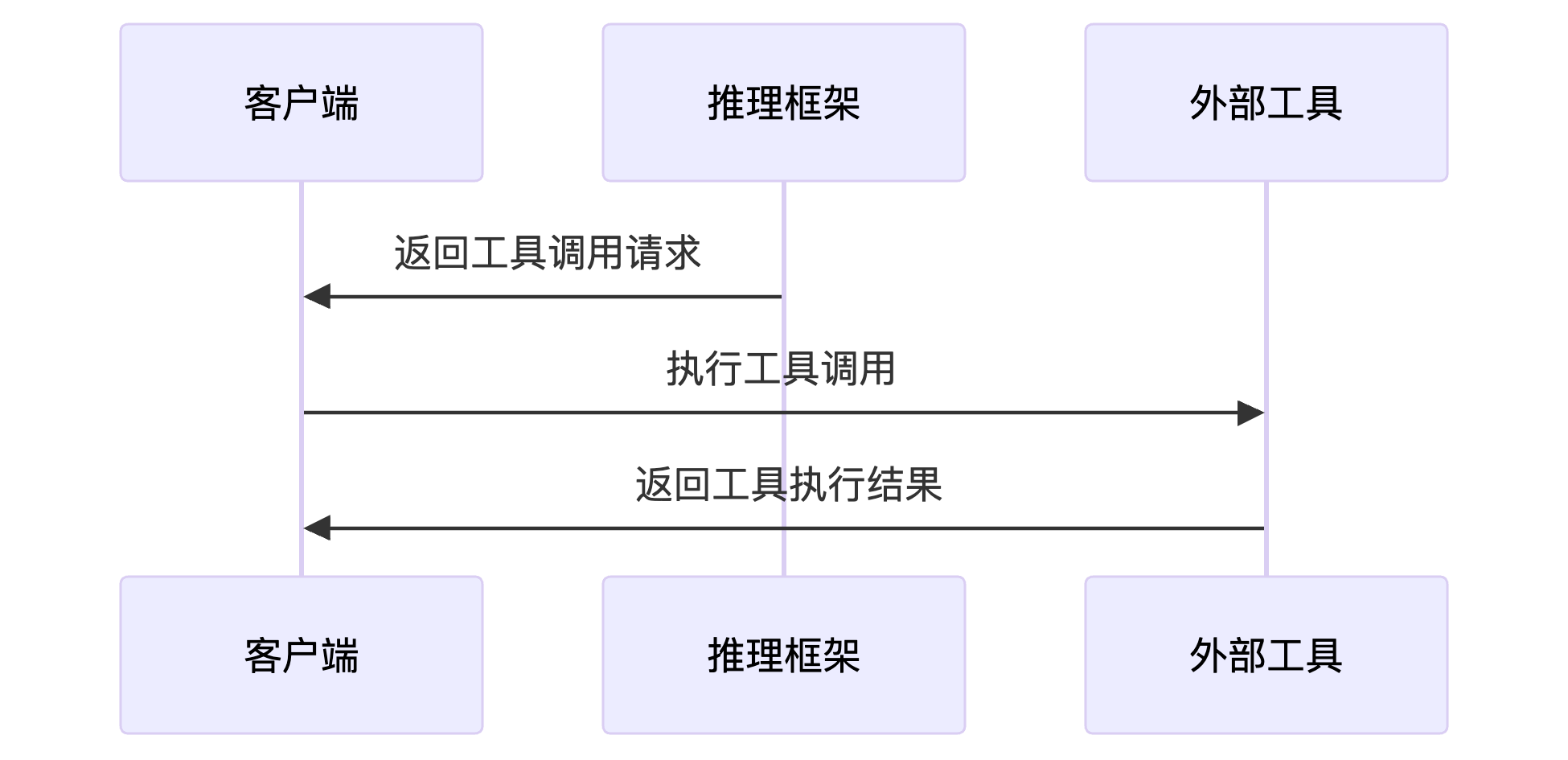
- 推理框架响应处理:框架解析模型输出,识别工具调用请求,提取函数名和参数,将其封装为标准化格式返回给客户端。
- 客户端工具调用:客户端根据工具调用请求,执行实际的工具函数,并将结果封装为消息,再次发送给模型。
- 模型最终响应:模型处理包含工具调用结果的请求,生成最终的对话补全响应,结束对话。
下图是本次工具调用的序列图:
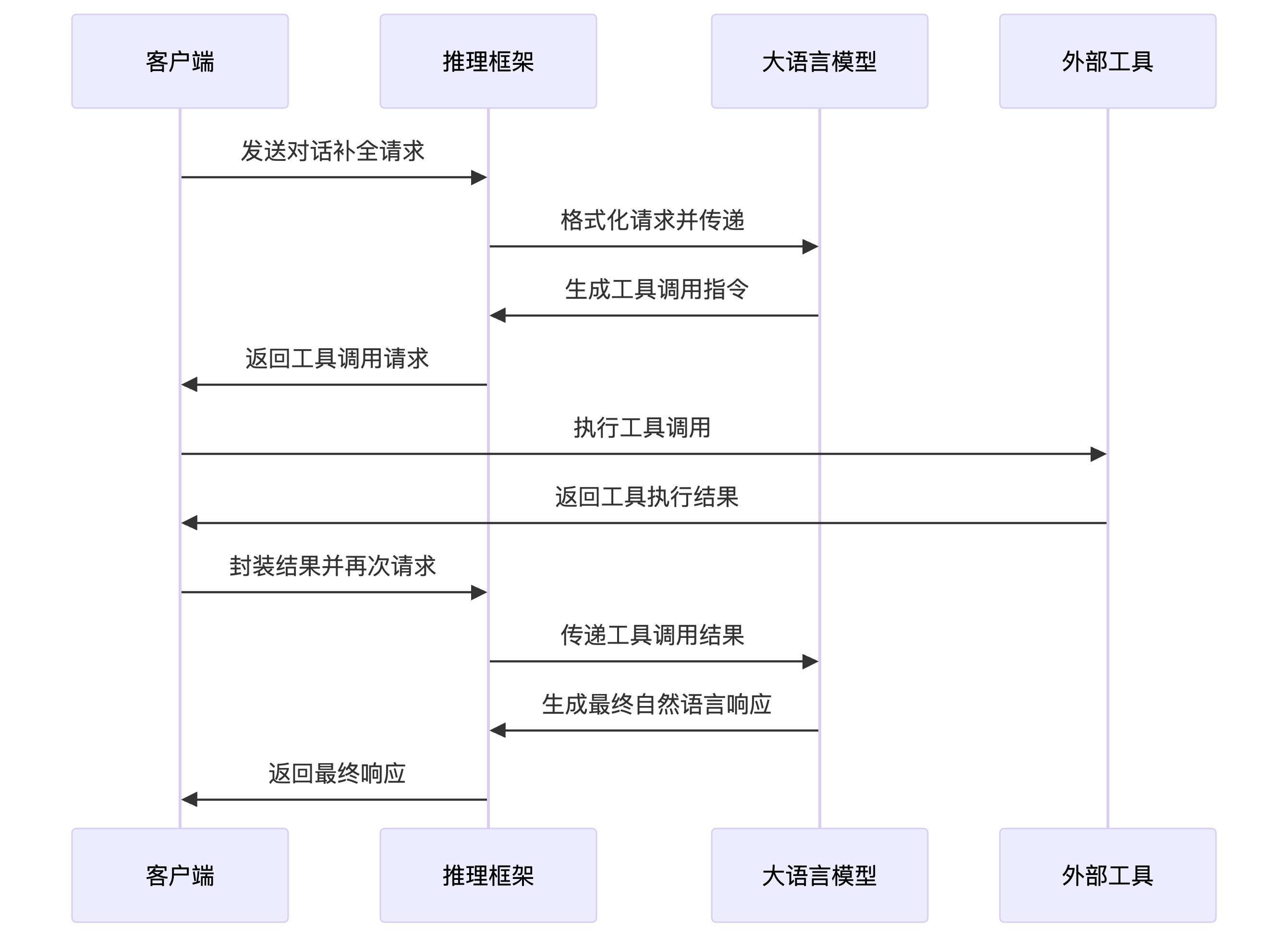
其中:
- 「客户端」是向大语言模型发起请求的主体
-
「推理框架」是在部署大语言模型时所涉及的对象,具体表现为一个兼容 OpenAI 的 WebService
LLM 推理框架是一个用于优化和加速 LLM 推理过程的软件工具或库。这些框架旨在提高推理效率、降低资源消耗,并支持多种量化方法、硬件加速技术、兼容标准调用协议。
常见的框架有 vLLM、llama.cpp、MindIE。
- 「大语言模型」则是核心的模型文件,它能够接收一段文本并完成内容补全。
- 「外部工具」是实际执行工具处理任务的所在,其形式具有多样性,既可能是客户端编写的一段 Python 函数,也可能是通过 Python 封装的外部 HTTP 请求。
1. 客户端:发送对话补全请求
客户端会构建包含工具描述的标准化请求,下面以加法器 number_adder 的调用为例进行说明。当需要进行工具调用时,我们需将工具描述作为请求参数的一部分。
一个完整的对话补全请求主要包含以下三个部分:
- 模型控制参数:例如
model 参数,用于明确指定所使用的模型版本。 - 消息主体:
messages 字段包含用户的提问内容,本次消息内容为3 + 2 =?。 - 工具描述:定义可调用的工具及其参数。本次提供了一个
number_adder 函数,该函数需要接受两个int 类型的参数a 和b,其功能是将两个数相加(Adds two numbers together)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"messages": [{"content": "3+2=?", "role": "user"}],
"model": "llama-3.3-70b-versatile",
"tools": [
{
"function": {
"description": "Adds two numbers together",
"name": "number_adder",
"parameters": {
"properties": {"a": {"type": "integer"}, "b": {"type": "integer"}},
"required": ["a", "b"],
"type": "object"
}
},
"type": "function"
}
]
}
2. 推理框架:格式化请求
推理框架接收到请求后,会按照特定的聊天模板对输入进行格式化处理。
以 LLaMA3.3 为例,处理后的消息格式如下:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out. If the given question lacks the parameters required by the function, also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"function": {
"description": "Adds two numbers together",
"name": "number_adder",
"parameters": {
"properties": {"a": {"type": "integer"}, "b": {"type": "integer"}},
"required": ["a", "b"],
"type": "object"
}
},
"type": "function"
}
]<|eot_id|><|start_header_id|>user<|end_header_id|>
3+2=?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|> // 给出start标签和角色,期望模型补全对话内容。
3. 大语言模型:生成工具调用指令
模型在处理请求后,会生成相应的工具调用响应:
1
[{"name": "number_adder", "parameters": {"a": 3, "b": 2}}]<|eom_id|>
因为此次是一条工具调用响应,涉及到多轮调用。模型在识别到该场景后,输出了代表消息结束的特殊标识符 <|eom_id> 而非此轮对话结束的标识符 <|eom_id>.
4. 推理框架:返回工具调用指令
推理框架在接收到模型响应后,会执行以下处理流程:
- 接收模型输出:获取模型生成的响应内容。
-
格式解析:对比预定义的聊天模板文件,解析响应格式。
一个可能的解析逻辑:
- 推理框架通过预定义的标识符
<|eom_id> 标识此次响应是一次工具调用 - 判断此次返回是否为合法的 JSON 对象。
- 推理框架通过预定义的标识符
- 参数提取:解析函数名及参数信息,提取函数名与参数信息。
- API 路由:将请求路由至相应的外部工具或 API。
- 执行与反馈:执行工具调用并返回标准化结果。
处理后,响应给调用方客户端的格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"choices": [
{
"finish_reason": "tool_calls",
"index": 0,
"message": {
"role": "assistant",
"tool_calls": [
{
"function": {
"arguments": "{\"a\": 3, \"b\": 2}",
"name": "number_adder"
},
"id": "call_2v4w",
"type": "function"
}
]
}
}
],
"created": 1739948216,
"id": "chatcmpl-415ee28a-5a46-4a8f-a4d5-2f9bd9b19c75",
"model": "llama-3.3-70b-versatile",
"object": "chat.completion",
"system_fingerprint": "fp_2ca0059abb",
"usage": {
"completion_tokens": 21,
"prompt_tokens": 223,
"total_tokens": 244
}
}
5. 客户端:模型调用方
需要再次明确的是,大模型本身并不直接进行工具调用,工具的实际调用发生在客户端。
以下是一个 Python 实现的工具调用示例,采用了 langGraph 相关开发框架:
1
2
3
4
5
6
# tool装饰器会将可调用(Callable或Runnable)对象转换为Tool(BaseTool)
@tool
def number_adder(a: int, b: int) -> int:
"""Adds two numbers together"""
logging.info(f"a: {a}, type_a: {type(a)}, b: {b}, type_b: {type(b)}")
return a + b
number_adder 函数调用完成后,客户端需要将工具调用的请求与工具调用的结果封装为消息,并再次请求聊天模型。此时请求中共有三条消息:
- 原始的请求。
"role": "user", "content": "3+2=?" - 助手的工具调用请求。
"role": "assistant", "content": "", "tool_calls": [{xxx}] -
工具返回的结果。
"role": "tool", "content": "5", "tool_call_id": "call_2v4w"
tool_call_id 主要用途是在并行工具调用时匹配调用请求和返回值
6. 客户端:封装工具调用结果并再次请求
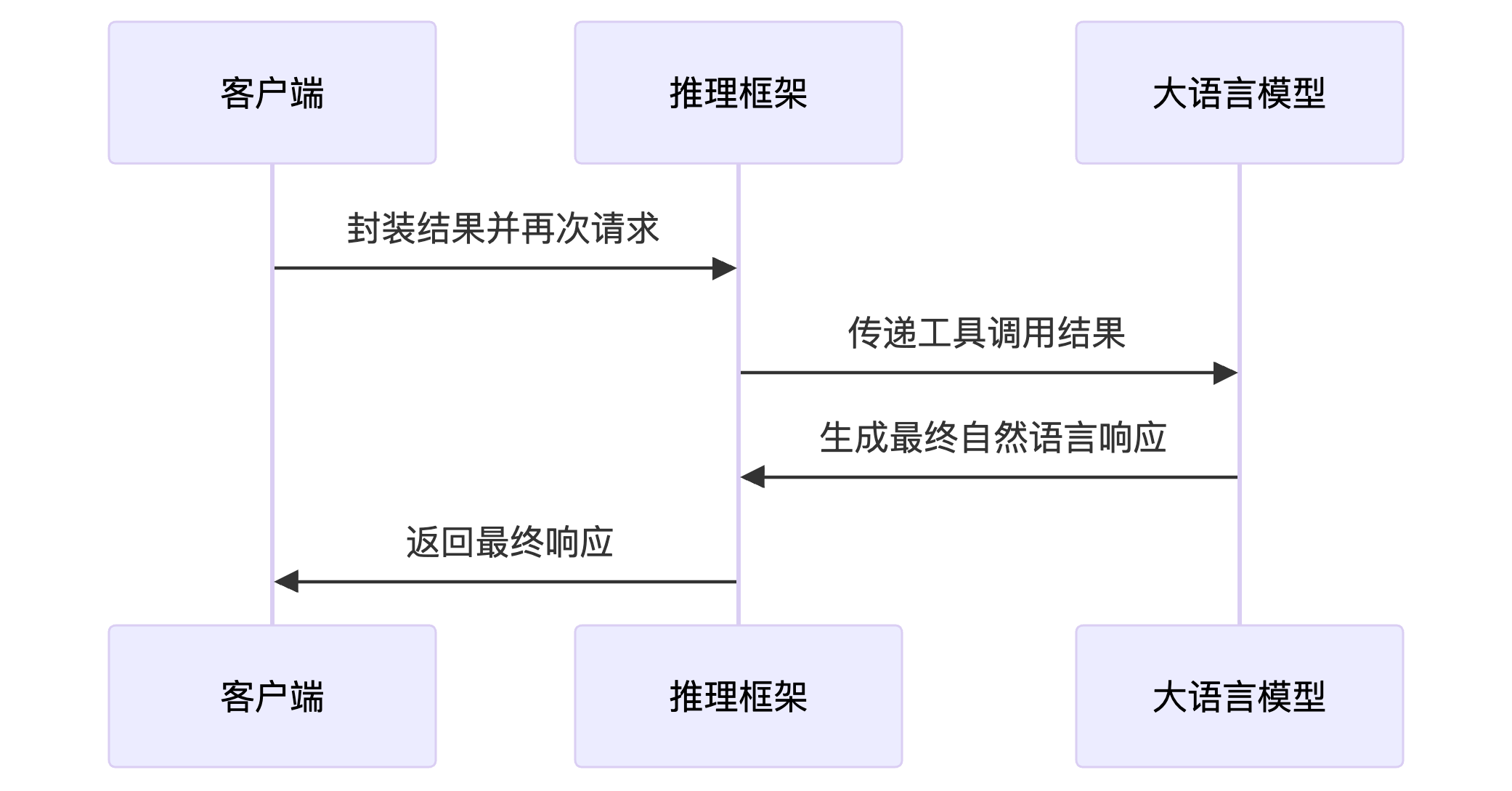
此次请求遵从同样的交互流程。唯一的区别是,此时的 LLM 调用包含三条消息,分别是原始的请求、助手的工具调用请求、工具返回的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
{
"messages": [
{"content": "3+2=?", "role": "user"},
{
"content": "",
"role": "assistant",
"tool_calls": [
{
"function": {"arguments": "{\"a\": 3, \"b\": 2}", "name": "number_adder"},
"id": "call_2v4w",
"type": "function"
}
]
},
{"content": "5", "role": "tool", "tool_call_id": "call_2v4w"}
],
"model": "llama-3.3-70b-versatile",
"tools": [
{
"function": {
"description": "Adds two numbers together",
"name": "number_adder",
"parameters": {
"properties": {"a": {"type": "integer"}, "b": {"type": "integer"}},
"required": ["a", "b"],
"type": "object"
}
},
"type": "function"
}
]
}
同样的,在客户端发送对话补全请求后,推理框架会依照聊天模板对请求进行格式化处理,并将其送入对话模型中进行推理。与前一次请求不同,此次模型判断请求不涉及工具调用,因此直接生成最终的对话补全内容。
1
The answer is 5.<|eot_id|>
其中,<|eot_id|> 是一个标识符,表示此轮对话调用的彻底结束,我们就得到了此次工具调用的结果:「The answer is 5. 」。
模型生成的响应内容将被推理框架进一步处理,并以标准化的格式返回给调用方。
最终的响应结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The answer is 5.",
"role": "assistant"
}
}
],
"created": 1739953891,
"id": "chatcmpl-5b6933a9-e109-4ba5-b966-3992d4569b20",
"model": "llama-3.3-70b-versatile",
"object": "chat.completion",
"system_fingerprint": "fp_e669a124b2",
"usage": {
"completion_tokens": 7,
"prompt_tokens": 255,
"total_tokens": 262
}
}
Tool Call 微调流程
在深入理解 LLM 的推理机制后,我们面临着一个关键的技术挑战:如何确保工具调用的稳定性和可靠性。具体而言,这涉及到两个核心问题:
- 首先,如何确保模型能够准确执行工具调用指令,而非直接生成回答;
- 其次,如何避免模型产生非标准结构的响应。
这些问题的解决需要在模型微调阶段进行系统性优化,使模型能够严格遵循工具调用的规范流程。下文中,我们假设工具调用的微调发生在 SFT 时期,即使用标注数据进行有监督训练。以下是一组标记数据(X-Y):
X: 今天是多少号?你的工具有:get_day, 参数为{"description":"Get today's date","name":"get_date","parameters":{"properties":{},"required":[],"type":"object"}}
Y: {"arguments":"","name":"get_date"}
LLaMA 3.3 微调
在 LLaMA3.3 模型中,微调流程通过引入一系列特殊的标记(special tokens)来支持多轮对话和工具调用:
-
<|begin_of_text|> : 表示提示(prompt)的开始,用于标识对话或任务的起始点。 -
<|end_of_text|> : 作为停止标识符,模型生成此标记后将停止生成更多内容。此标记仅由基础模型生成。 -
<|start_header_id|> 和 <|end_header_id|> : 这些标记用于封装特定消息的角色信息。可能的角色包括:system(系统)、user(用户)、assistant(助手)和ipython(该角色是 LLaMA 独有的)。 -
<|eom_id|> : 表示消息结束(End of Message)。消息表示执行的可能停止点,模型可以在此通知执行者需要进行工具调用,需要进行多步骤交互。 -
<|eot_id|> : End of turn。表示模型已经确定它已完成与用户消息的互动,有两种情况会使用:- 在模型与用户之间的直接互动结束时
- 在模型与任何可用工具之间的多次互动结束时
- 其他标签,略
在工具调用的场景中,我们实际上将工具的描述信息作为 Prompt 的一部分输入到模型中,使模型能够理解并正确调用外部工具。以下是一个天气查询接口的描述示例,我们将通过这个例子来具体分析工具调用是如何被整合到训练数据中的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[
{
"description": "Get weather info for places",
"name": "get_weather",
"parameters": {
"properties": {
"city": {"description": "The name of the city to get the weather for", "type": "string"},
"metric": {"default": "celsius", "description": "The metric for weather. Options are: celsius, fahrenheit", "type": "string"}
},
"required": ["city"],
"type": "dict"
}
}
]
在 LLaMA3.3 模型中,这一描述会被包含在系统消息中,紧接着是用户的具体请求内容。当我们提供一个天气查询接口时,该接口的描述信息会被嵌入到系统提示(System Prompt)中,作为训练数据的一部分。以下是一个完整的示例,展示了系统提示、用户请求以及模型期望的响应格式:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out. If the given question lacks the parameters required by the function, also point it out. You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.
[
{
"description": "Get weather info for places",
"name": "get_weather",
"parameters": {
"properties": {
"city": {"description": "The name of the city to get the weather for", "type": "string"},
"metric": {"default": "celsius", "description": "The metric for weather. Options are: celsius, fahrenheit", "type": "string"}
},
"required": ["city"],
"type": "dict"
}
}
]<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the weather in SF and Seattle?<|eot_id|>
<|start_header_id|>assistant<|end_header_id|> // 给出start标签和角色,期望模型补全对话内容。
由于我们希望模型能够正常响应工具调用,因此我们选用的标签数据是一次成功的调用结果:
为了确保模型能够正确响应工具调用请求,我们在训练数据中选择成功的工具调用结果作为标签数据。以下是一个具体的示例:
[get_weather(city='San Francisco', metric='celsius'), get_weather(city='Seattle', metric='celsius')]<|eot_id|>
在这个示例中,模型根据用户查询「What is the weather in SF and Seattle?」生成了两个工具调用请求,分别针对旧金山(San Francisco)和西雅图(Seattle),并指定了温度单位为摄氏度(celsius)。<|eot_id|> 表示已经结束了当前轮次的响应。
以上就是 LLaMA3.3 在 Tool Call 微调中的细节。
回到之前的问题:工具调用的触发机制是怎样的?
从底层架构来看,支持工具调用的对话模型本质上仍遵循文本生成范式。当用户输入进入模型推理流时,系统通过以下两种补全策略:
-
直接响应,而不调用工具
此时模型直接生成自然语言响应,例如:
1
Sunny weather in San Francisco, rainy weather in Seattle<|eot_id|>
-
调用工具
模型生成工具调用请求,例如:
[{"name": "get_weather", "parameters": {"city": "San Francisco", "metric": "celsius"}}, {"name": "get_weather", "parameters": {"city": "Seattle", "metric": "celsius"}}]<|eot_id|>
针对工具调用和结构化输出场景微调的对话模型,经过了 STF 或 RLHF 学习后,能够有效区分是否需要结构化工具调用。在需要时,模型通常会以较高的概率选择调用工具。
Qwen2 微调流程
Qwen2 在支持工具调用时采用了独特的模板化方法,而非依赖于特殊标记。
Qwen2 采用了自己独有的工具调用模板,而在 Qwen2.5 中同时支持了标准 GTP 和 Qwen2 的的工具调用模板。
以下是官方在 Qwen2.5 中的介绍:
此外,Qwen2.5 支持 vllm 的内置工具调用。此功能需要 vllm>=0.6 。您可以使用与调用 GPT 工具相同的方式进行使用。Qwen2.5 的聊天模板中也包含了一个工具调用模板,这意味着你可以使用 Hugging Face transformers’ tool calling support.
vLLM / Ollama / Transformers 的工具调用支持使用受 Nous’ Hermes 的格式启发的工具调用模板。 此前 [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) 提供了使用 Qwen2 **自己的工具调用模板**的工具调用支持(这较难与 vllm 和 Ollama 集成),而 Qwen2.5 既保持了与 Qwen2 模板和 Qwen-Agent 的兼容性。
Qwen2 的工具调用模板主要包含以下几部分:
- 系统提示(System Prompt):定义了模型的行为规范和任务目标。
- 用户提示(User Prompt):包含了用户的实际请求内容。
- 工具信息(Tool Information):详细描述了可调用工具的功能、输入参数和使用方式。
- 工具调用指令(Tool Invocation Instructions):明确了工具调用的格式要求。
其在聊天模板上,采用了与
gpt-3.5-turbo 类似的标记方式。如,<|im_start|> 和<|im_end|> 表示一条消息的开始和结尾,并未引入额外的特殊标记(如<|eom_id|>\<|eot_id|>)。
与 LLaMA3.3 一样,Qwen 也将工具调用放入了 System Prompt 作为提示词。不同点在于,其针对工具调用场景,单独格式化工具描述是,而非直接将工具描述的 JSON 放入其中。(为了展示,下方将 \n 以换行方式展示):
<|im_start|>system
You are a helpful assistant.
# 工具
## 你拥有如下工具:
### {number_adder}
将两个数相加,返回相加的结果
输入参数:{"properties":{"a":{"type":"integer"},"b":{"type":"integer"}},"required":["a","b"],"type":"object"}
此工具的输入应为JSON对象。
## 你可以在回复中插入零次、一次或多次以下命令以调用工具:
✿FUNCTION✿: 工具名称,必须是[{number_adder}]之一。
✿ARGS✿: 工具输入
✿RESULT✿: 工具结果
✿RETURN✿: 根据工具结果进行回复,需将图片用渲染出来<|im_end|>
<|im_start|>user
你好,请问3+2等于几<|im_end|>
<|im_start|>assistant // 给出start标签和角色,期望模型补全对话内容。
当模型需要调用工具时,其输出将遵循以下固定格式:
✿FUNCTION✿: number_adder。
✿ARGS✿: {"a": 3, "b": 2}
✿RESULT✿: 5
✿RETURN✿: 3 + 2 的结果是5
参考内容
- https://zhuanlan.zhihu.com/p/713937194
- https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_3/
- https://qwen.readthedocs.io/zh-cn/latest/framework/function_call.html
- https://qwenlm.github.io/blog/qwen2.5/
- https://huggingface.co/docs/transformers/main/en/chat_templating
- https://huggingface.co/blog/zh/unified-tool-use