这是 Kubernetes 基础理论中,关于 Service 部分的内容。
前言
Kubernetes 之所以引入 Service 机制,主要是因为 Pod 资源不能够对外稳定的第提供服务。
- 一方面是因为 Pod 的 IP 并非固定,其生命周期不是并永久的,会伴随着应用的启动、崩溃、扩容、缩容而不断变化。
- 另一方面则是为了满足一组 Pod 需要进行服务发现和负载均衡以对外提供服务的需求。
Service 作为一种抽象机制,为提供相同服务的一组 Pod 提供了一个稳定的网络入口。Service 通过创建不变的 IP 地址和 DNS 名称,确保了服务的连续性和可访问性,避免了 Pod 频繁地创建和销毁导致的在访问时的复杂问题。
因此,Service 成为了 Kubernetes 中实现微服务架构和保障服务间通信稳定性的核心组件。
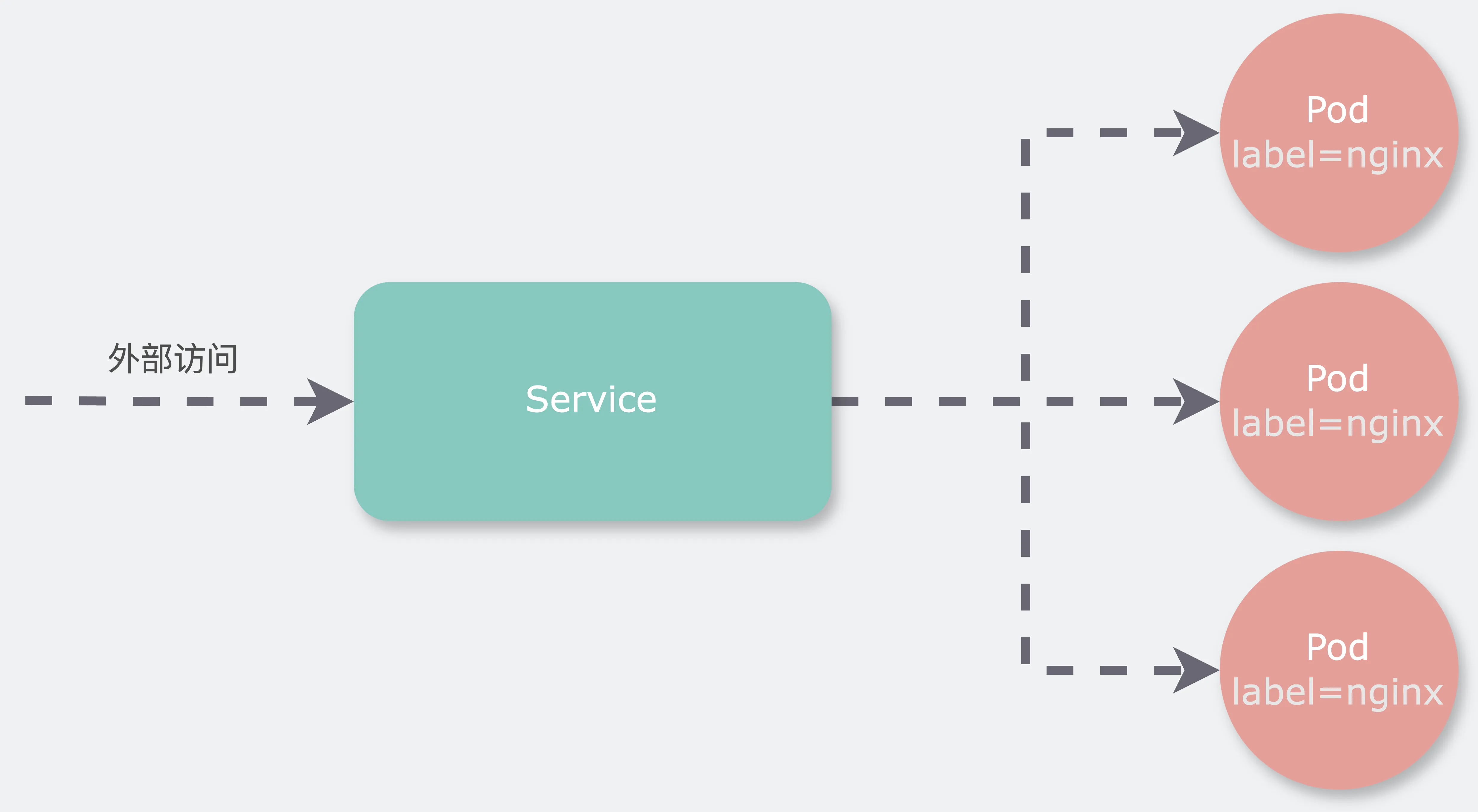 Service与Pod的关系
Service与Pod的关系
Service 资源定义
以下内容是一个典型的 Service 资源的 YAML 文件基本结构。典型的Service资源配置文件需要确定哪些Pod会被选择,以及应该如何确定Service的端口与Pod端口的对应关系。
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Service
metadata:
name: nginx-service # 服务名称
spec:
selector: # Pod选择器
app.kubernetes.io/name: nginx
ports:
- name: name-of-service-port # 服务的端口标识名
protocol: TCP # 传输层类型
port: 80 # 服务端口
targetPort: 8080 # Pod端口名
Service 类型(访问方式)
在 Kubernetes 中,Service 提供了多种访问方式,这些方式决定了 Service 如何向集群内部或外部的客户端暴露。这些方式的核心在于 Service 如何向 Kubernetes 集群进行服务注册,从而确保集群内部的 Pod 与 Service 之间的发现与通信。具体而言,对于集群内部的 Pod,它们可以通过以下几种方法访问 Service:
- 通过 Pod 启动时的环境变量,直接访问 Service 的 IP 地址。
- 通过 DNS 解析 Service,直接访问 Service 的 IP 地址。
- 通过 DNS 解析 Service,获取后端 Pod 的 IP 地址,进而访问实际的后端 Pod。
至于 Service 暴露给集群外部客户端的方式,Kubernetes 提供了四种不同的访问方式,分别是 ClusterIP、NodePort、LoadBalancer 和 ExternalName。这些方式各具特点,可根据实际需求选择适合的暴露方式。
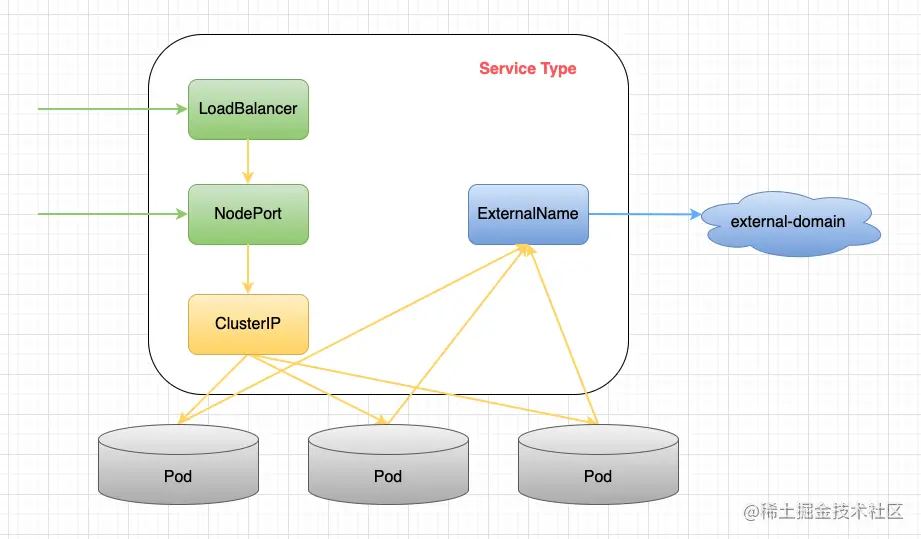
4种Service的区别联系
4种Service的区别联系
| 访问方式 | 说明 |
|---|---|
ClusterIP(默认方式) |
服务只能够在集群内部可以访问,通过集群的内部 IP 暴露服务,这也是默认的 ServiceType。 |
NodePort(向外暴露) |
可以从集群的外部访问一个 NodePort 服务。通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会自动创建一个 ClusterIP 服务,外部请求首先到达 NodePort,然后被转发到 ClusterIP |
LoadBalancer(向外暴露) |
和 nodePort 类似,不过除了使用一个 Cluster IP 和 nodePort 之外,还会向所使用的公有云申请一个负载均衡器,实现从集群外通过 LB 访问服务。 使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。 |
ExternalName |
此模式主要面向运行在集群外部的服务,通过它可以将外部服务映射进 k8s 集群。 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。 没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。 |
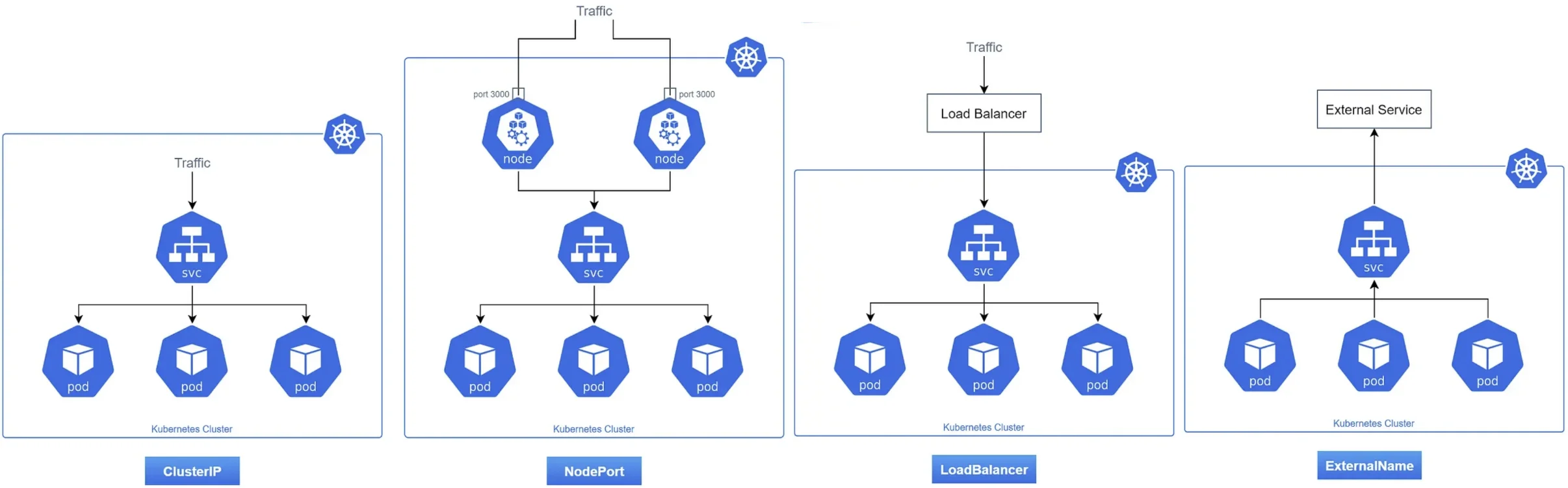
四种类型的Service访问示意
四种类型的Service访问示意
对于一个普通的 Service(仅限于 ClusterIP、NodePort、LoadBalancer),Kubernetes 通过为其分配一个集群内部可访问的 Cluster IP,实现了集群内对 Service 的访问。
除此之外,还存在一种 Headless Service 方式。在使用 Headless Service 时,该 Service 不会被分配 Cluster IP,也不依赖 kube-proxy 进行反向代理和负载均衡处理。当客户端尝试访问此类 Service 时,DNS 服务器会通过 A 记录将 headless service 的后端 Pod IP 列表直接解析并呈现出来,从而使客户端能够自主选择并访问所需的具体 Pod。
Service 对集群之外暴露服务的主要方式有两种:NodePort 和 LoadBalancer,但是这两种方式,都有一定的缺点:
- NodePort 方式的缺点是会占用很多集群机器的端口
- LoadBalancer 的缺点是每个 Service 都需要一个 LB,并且需要 kubernetes 之外的设备的支持。
基于这种现状,kubernetes 提供了 Ingress 资源对象,Ingress 只需要一个 NodePort 或者一个 LB 就可以满足暴露多个 Service 的需求。它由位于 Kubernetes 边缘节点(这样的节点可以是很多个也可以是一组)的 Ingress controller 驱动,负责管理南北向流量。
K8s 资源的通信流程
Pod 和 Service 作为 K8s 的核心抽象,仅仅定义这些抽象资源是不够的,我们还需明确它们相互访问的具体流程。毕竟,网络无法触及一个纯粹的抽象概念。为此,Pod 必须绑定一个实际的 IP 地址以供访问(Service 则不一定),而 Pod 在访问 Service 时也需要一个 IP 地址,这是确保其核心功能正常运转的必要前提。
Pod 内 Container 间通讯
在一个 Pod 内部,多个容器会共享同一个网络命名空间,这意味着每个容器均享有与 Pod 相同的 IP 地址和端口地址空间。此外,由于这些容器均处于同一个网络命名空间中,它们能够便捷地通过 localhost 实现相互通信。
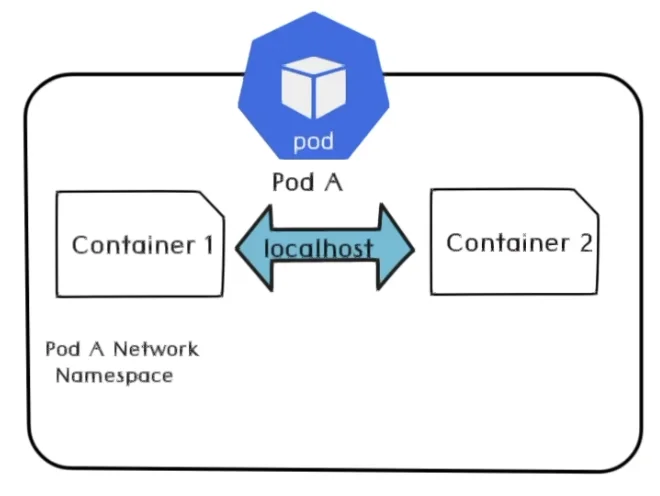
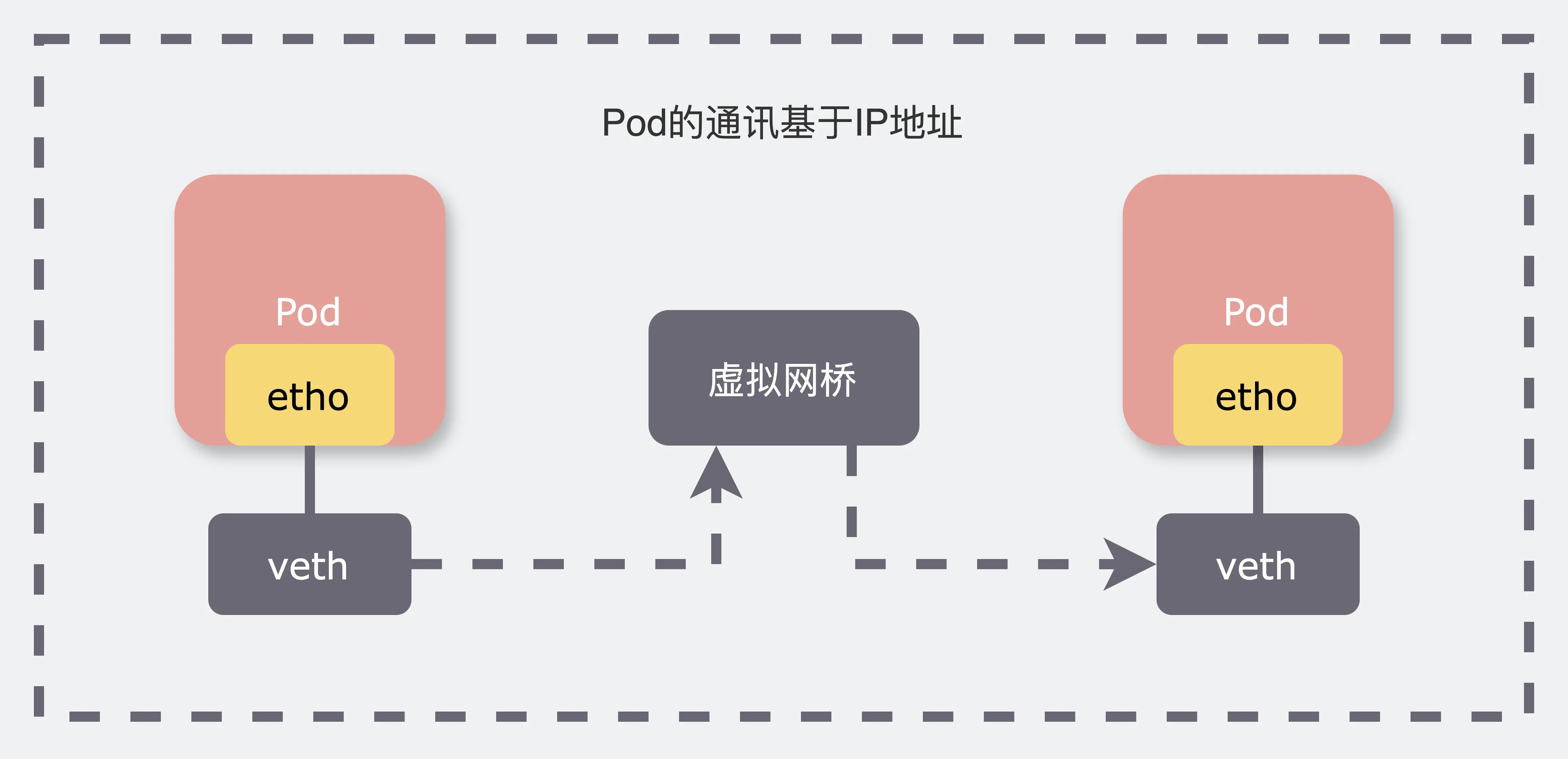
Pod 与 Pod 的通讯
Pod 在宿主机节点上运行,并通过虚拟网卡(veth pair)与节点进行通信。Node 节点内部的虚拟网桥(例如 10.1.0.1/24)负责发现并连接独立 IP 主机。当 PodA 需要访问 PodB 时,报文会通过 eth0 发送,并由虚拟网桥转发至目标网卡,从而实现通讯。
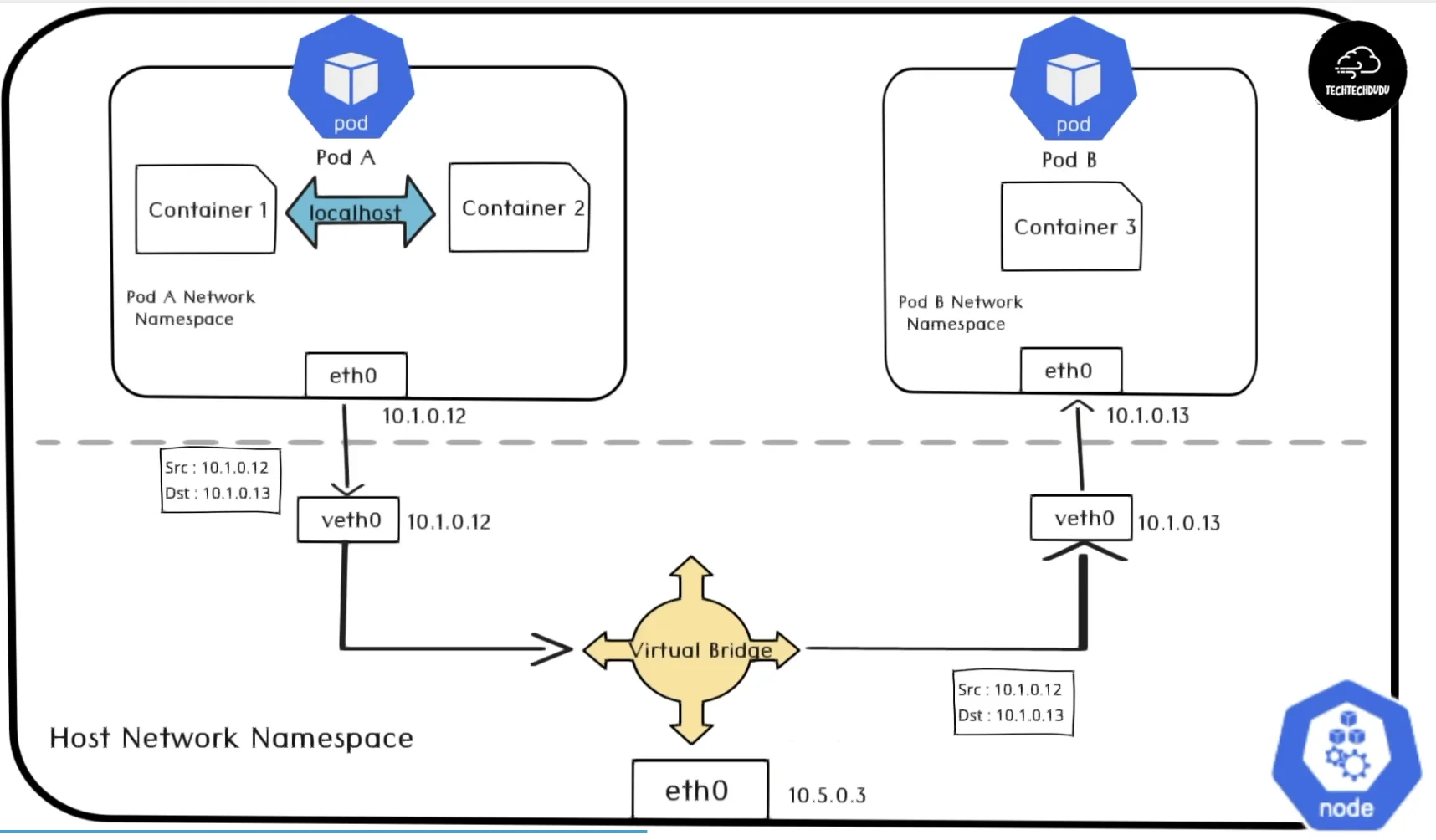
一个Node中的两个Pod的通讯流程。(疑问:虚拟网桥作为链路层设备,图中所示是否意味着它能转发IP报文?)
一个Node中的两个Pod的通讯流程。(疑问:虚拟网桥作为链路层设备,图中所示是否意味着它能转发IP报文?)
Pod 与 Service 通讯
假设 Service1 的一个 Pod A 和 Service2 的一个 Pod C 分别位于两个节点。
-
ServiceA 发送的数据包的目标 IP 地址是 Service2 的 IP 地址,根据虚拟网桥的路由表,路由至 iptables 或 IPVS
以 iptables 为例,此时 iptables 将目标 IP 地址改写为 10.1.1.17,即 Service2 的其中一个 pod 的 endpoint 地址。iptables 由 kube-proxy 进行维护,见 Kube-proxy
- 数据包经过节点的网口 etho0 来到集群网络,并被路由到 Pod C 所在节点
- 数据包再经由 iptables、虚拟网桥和 veth0 最终找到对应的 PodC
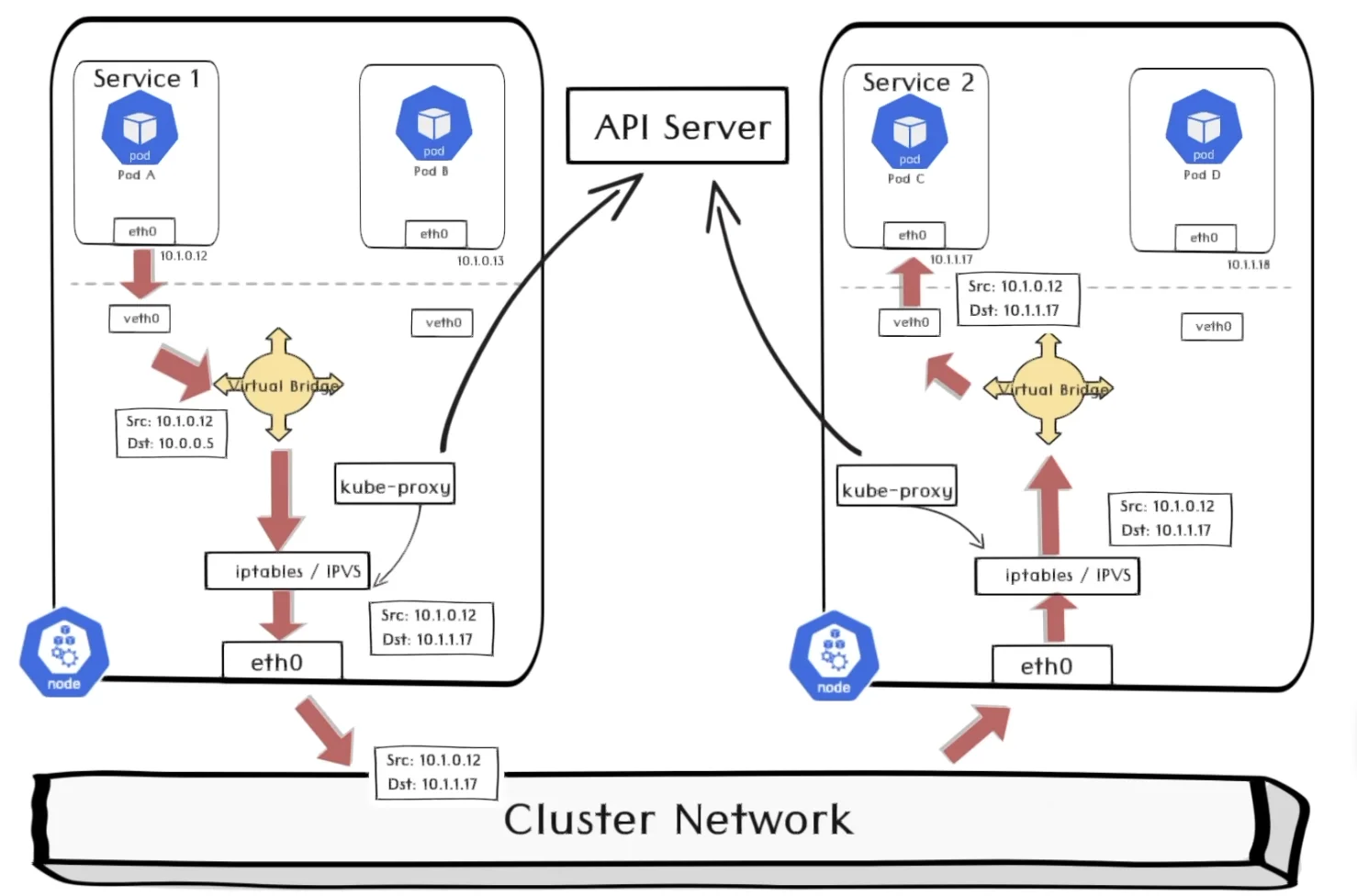
一个集群内部的中的两个Service是如何通讯的
一个集群内部的中的两个Service是如何通讯的
Kube-proxy
Service 在很多情况下只是一个概念,Pod 将服务注册到 Service,真正实现提供服务发现与负载均衡的其实是 kube-proxy 服务进程。每个 Node 节点上都运行着一个 kube-proxy 服务进程,当创建 Service 的时候会通过 api-server 向 etcd 写入创建的 service 信息,而 kube-proxy 会基于监听的机制发现这种 Service 的变动,然后它会将最新的 Service 信息转换成对应的访问规则。
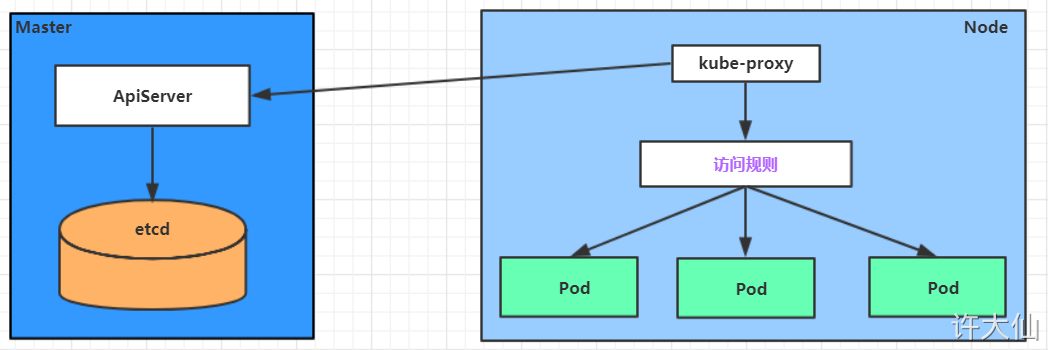
示意图
示意图
kube-proxy 组件负责实现除 ExternalName 之外的虚拟 IP 机制服务。每个 kube-proxy 实例都会监视 Kubernetes 控制平面用于添加和删除 Service 和 EndpointSlice 对象。对于每个服务,kube-proxy 调用适当的 API(取决于 kube-proxy 模式)来配置节点规则以分配 Service 的 clusterIP 和的流量,并将该流量重定向到服务的端点之一(端点通常是 Pod,但可能是用户提供的任意 IP 地址)。
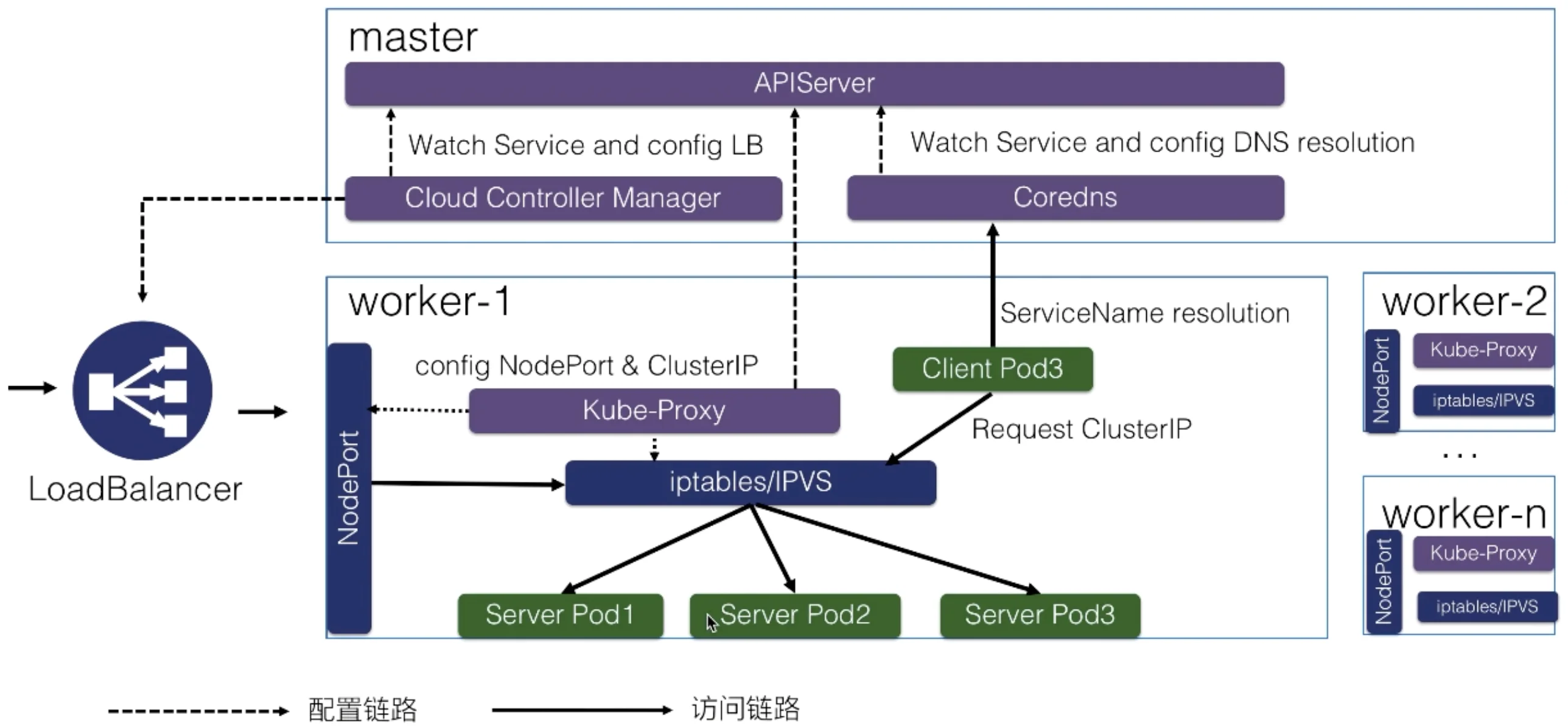
Service 负载均衡与服务发现架构
Service 负载均衡与服务发现架构
iptables
此代理模式仅适用于 Linux 节点。
常见的代理模式就是直接使用 iptables 转发当前节点上的全部流量,这种脱离了用户空间在内核空间中实现转发的方式能够极大地提高 proxy 的效率,增加 kube-proxy 的吞吐量。
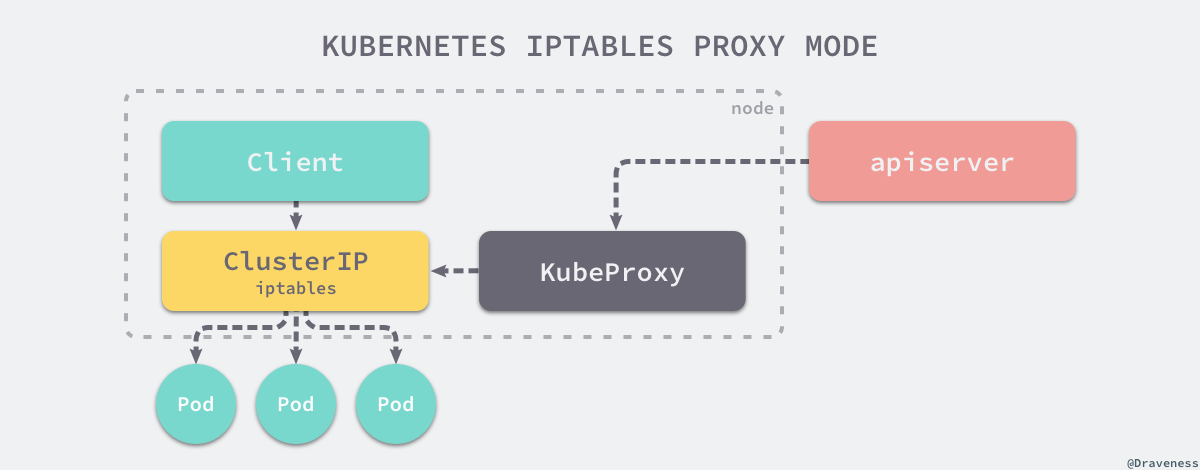
kube-proxy只用于更新iptables规则
kube-proxy只用于更新iptables规则
看起来 service 是个完美的方案,可以解决服务访问的所有问题,但是 service 这个方案(iptables 模式)也有自己的缺点。
- 首先,如果转发的 pod 不能正常提供服务,它不会自动尝试另一个 Pod,当然这个可以通过
readiness probes 来解决,主动发现不正常的 Pod。 -
nodePort 类型的服务也无法添加 TLS 或者更复杂的报文路由机制。因为只做了 NAT - iptables 规则同步的效率问题
IPVS
ipvs 就是用于解决在大量 Service 时,iptables 规则同步变得不可用的性能问题。与 iptables 比较像的是,ipvs 的实现虽然也基于 netfilter 的钩子函数,但是它却使用哈希表作为底层的数据结构并且工作在内核态,这也就是说 ipvs 在重定向流量和同步代理规则有着更好的性能。
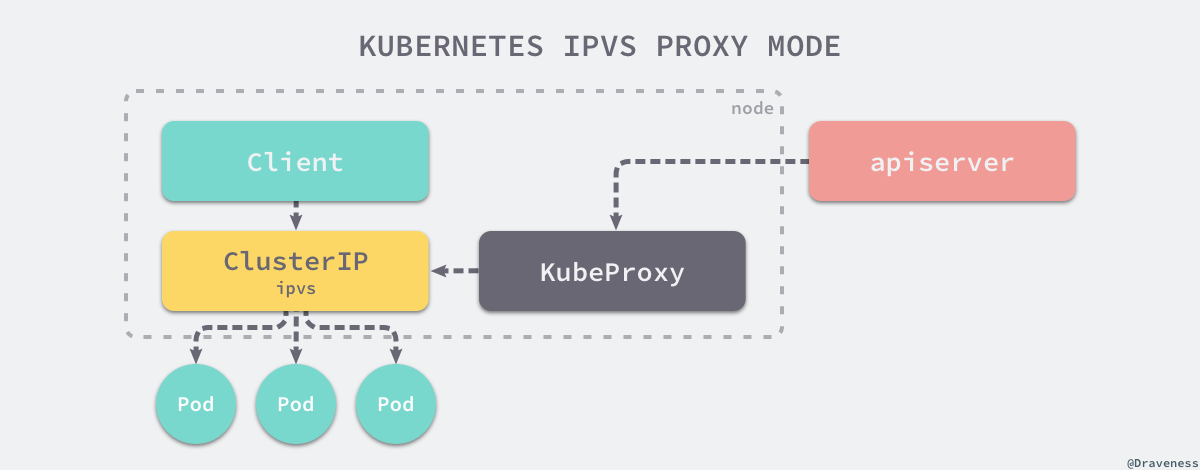
ipvs 模式下,kube-proxy 会先创建虚拟网卡,k8s 通过 kube-proxy 将每一个 service cluster ip 绑定到虚拟网卡 kube-ipvs0,同时在路由表中增加一些 ipvs 的路由条目。而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式来作为负载均衡策略。、
ipvs 是一个内核态的四层负载均衡(Load Balence,LB),支持 NAT 以及 IPIP 隧道模式,但 LB 和 RS 不能跨子网,IPIP 性能次之,通过 ipip 隧道解决跨网段传输问题,因此能够支持跨子网。而 NAT 模式没有限制,这也是唯一一种支持端口映射的模式。
但是 ipvs 只有 NAT(也就是 DNAT),NAT 也俗称三角模式,要求 RS 和 LVS 在一个二层网络,并且 LVS 是 RS 的网关,这样回包一定会到网关,网关再次做 SNAT,这样 client 看到 SNAT 后的 src ip 是 LVS ip 而不是 RS-ip。默认实现不支持 ful-NAT,所以像公有云厂商为了适应公有云场景基本都会定制实现 ful-NAT 模式的 lvs。
我们不难猜想,由于 Kubernetes Service 需要使用端口映射功能,因此 kube-proxy 必然只能使用 ipvs 的 NAT 模式。
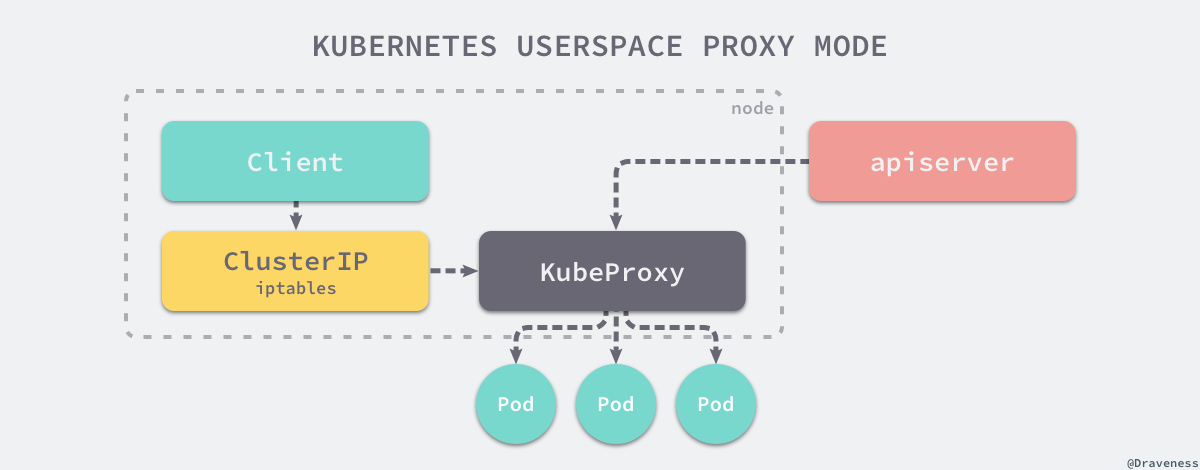
userspace 模式
「资源开销大,废弃」
所有连接到当前代理端口的请求都会被转发到 Service 背后的一组 Pod 上,它其实会在节点上添加 iptables 规则,通过 iptables 将流量转发给 kube-proxy 处理。
Service 与 DNS
DNS 在 K8s 的 Service 中的作用是服务发现,其不被用于实现负载均衡,原因可能有:
- DNS 实现的历史由来已久,它不遵守记录 TTL,并且在名称查找到结果后会对其进行缓存。
- 有些应用程序仅执行一次 DNS 查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS 记录上的 TTL 值低或为零也可能会给 DNS 带来高负载,从而使管理变得困难。
当 Service 和 Pod 需要相互访问时,它们可以通过 DNS 解析和环境变量实现服务发现:
-
DNS 解析
Kubernetes 集群内部有一个内置的 DNS 服务,它会为每个 Service 分配一个 DNS 名称。例如,一个名为
my-service 的 Service 在my-namespace 命名空间中,其 DNS 名称将是my-service.my-namespace.svc.cluster-domain.example。Pod 可以通过这个 DNS 名称来解析 Service 的 Cluster IP。 -
环境变量
在 Pod 启动时,Kubernetes 会自动注入一些环境变量,这些环境变量包含了集群中所有 Service 的信息。Pod 可以通过这些环境变量来获取 Service 的 IP 和端口信息。然而,这种方式不如 DNS 解析灵活,因为它要求 Pod 必须在 Service 之后启动。
Pod 与 Service 的 DNS 记录包括:
-
Services
除了 Headless Service 之外的 Service 会被赋予一个形如
my-svc.my-namespace.svc.cluster-domain.example 的 DNS A/AAAA 记录没有集群 IP 的 Headless Service 也会被赋予一个形如
my-svc.my-namespace.svc.cluster-domain.example 的 DNS A/AAAA 记录。 与普通 Service 不同,这一记录会被解析成对应 Service 所选择的 Pod IP 的集合。 客户端要能够使用这组 IP,或者使用标准的轮转策略从这组 IP 中进行选择。((20240813092252-ka7v6wb “SRV 记录”)):Kubernetes 根据普通 Service 或 Headless Service 中的命名端口创建 SRV 记录。每个命名端口, SRV 记录格式为
_port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.example。- 普通 Service,该记录会被解析成端口号和域名:
my-svc.my-namespace.svc.cluster-domain.example - 无头 Service,该记录会被解析成多个结果,及该服务的每个后端 Pod 各一个 SRV 记录, 其中包含 Pod 端口号和格式为
hostname.my-svc.my-namespace.svc.cluster-domain.example 的域名。
- 普通 Service,该记录会被解析成端口号和域名:
-
Pods
当前,创建 Pod 时其主机名(从 Pod 内部观察)取自 Pod 的
metadata.name 值。不是每个 pod 都会向 DNS 注册,只有:
- StatefulSet 中的 POD 会向 dns 注册,因为他们要保证顺序行
- POD 显式指定了 hostname 和 subdomain,说明要靠 hostname/subdomain 来解析
- Headless Service 代理的 POD 也会注册
- 服务发现 :DNS 提供了一种方便的方式来发现 Service 的 IP 地址。当一个 Pod 需要访问某个 Service 时,它可以通过 DNS 域名来查找 Service 的 IP 地址,而不需要知道 Service 的具体 IP 地址。这种方式极大地简化了配置和维护工作。
- 资源与 IP 解耦 :通过使用 DNS 域名,Pod 和 Service 之间的依赖关系从具体的 IP 地址解耦出来。这意味着即使 Service 的 IP 地址发生变化(例如,Service 重启或扩展),Pod 仍然可以通过相同的 DNS 域名来访问 Service,而不需要更新配置。
- 简化配置 :使用 DNS 域名使得 Pod 和 Service 的配置更加简洁和易于管理。Pod 只需要知道 Service 的域名,而不需要复杂的 IP 地址配置。
- 命名空间隔离 :DNS 通过在域名中包含命名空间信息,确保了不同命名空间中的同名 Service 可以被正确解析和访问。
- 集成其他服务 :DNS 服务可以与其他外部服务集成,使得 Kubernetes 集群内的服务可以与外部服务进行无缝通信。
参考内容:
- [Kubernetes] Service Overview
- Service详解之Service介绍
- 详解 Kubernetes Service 的实现原理
- Kube-proxy 详解
- Kubernetes 网络模型进阶